Merge pull request #11412 from lucperkins/lperkins/docs-restructuring-v2
Restructure documentation source filesrelease-3.5
commit
3898452b54
|
|
@ -1 +0,0 @@
|
|||
docs.md
|
||||
|
|
@ -0,0 +1,5 @@
|
|||
# The etcd documentation
|
||||
|
||||
etcd is a distributed key-value store designed to reliably and quickly preserve and provide access to critical data. It enables reliable distributed coordination through distributed locking, leader elections, and write barriers. An etcd cluster is intended for high availability and permanent data storage and retrieval.
|
||||
|
||||
Please note that the files in this directory are *source files* for the built and rendered documentation that can be viewed at [etcd.io/docs](https://etcd.io/docs).
|
||||
|
|
@ -0,0 +1,5 @@
|
|||
---
|
||||
title: etcd version ___
|
||||
---
|
||||
|
||||
These docs cover everything from setting up and running an etcd cluster to using etcd in applications. Improvements to these docs are encouraged through [pull requests](https://help.github.com/en/articles/about-pull-requests) to the [etcd project](https://github.com/etcd-io/etcd) on GitHub.
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
---
|
||||
title: Benchmarks
|
||||
---
|
||||
|
|
@ -1,5 +1,6 @@
|
|||
---
|
||||
title: Branch management
|
||||
weight: 1
|
||||
---
|
||||
|
||||
## Guide
|
||||
|
|
@ -1,16 +1,17 @@
|
|||
---
|
||||
title: Demo
|
||||
weight: 1
|
||||
---
|
||||
|
||||
This series of examples shows the basic procedures for working with an etcd cluster.
|
||||
|
||||
## Set up a cluster
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/01_etcd_clustering_2016051001.gif" alt="01_etcd_clustering_2016050601"/>
|
||||
|
||||
|
||||
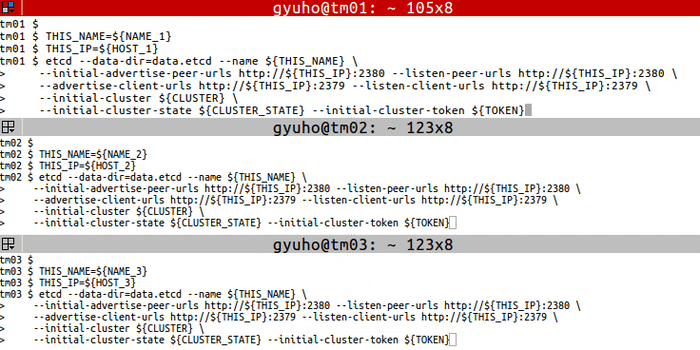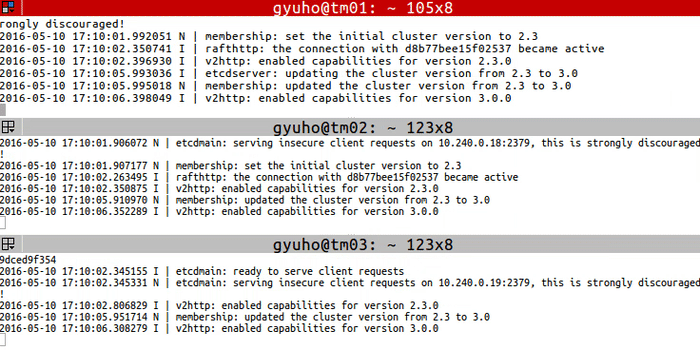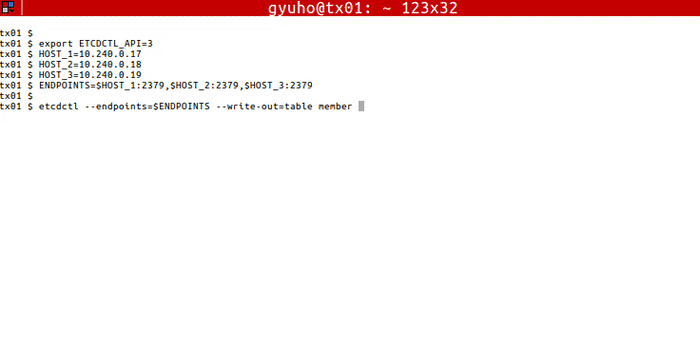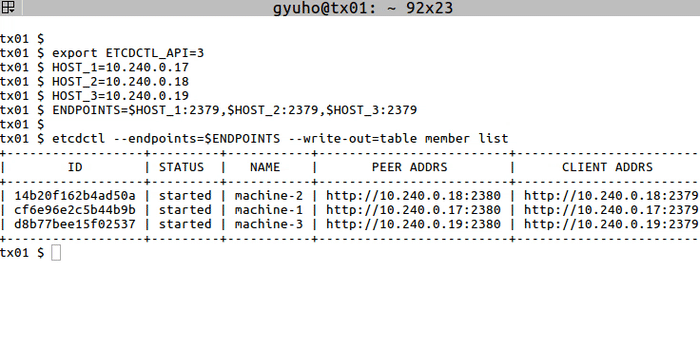
On each etcd node, specify the cluster members:
|
||||
|
||||
```
|
||||
```shell
|
||||
TOKEN=token-01
|
||||
CLUSTER_STATE=new
|
||||
NAME_1=machine-1
|
||||
|
|
@ -24,7 +25,7 @@ CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3
|
|||
|
||||
Run this on each machine:
|
||||
|
||||
```
|
||||
```shell
|
||||
# For machine 1
|
||||
THIS_NAME=${NAME_1}
|
||||
THIS_IP=${HOST_1}
|
||||
|
|
@ -55,7 +56,7 @@ etcd --data-dir=data.etcd --name ${THIS_NAME} \
|
|||
|
||||
Or use our public discovery service:
|
||||
|
||||
```
|
||||
```shell
|
||||
curl https://discovery.etcd.io/new?size=3
|
||||
https://discovery.etcd.io/a81b5818e67a6ea83e9d4daea5ecbc92
|
||||
|
||||
|
|
@ -97,7 +98,7 @@ etcd --data-dir=data.etcd --name ${THIS_NAME} \
|
|||
|
||||
Now etcd is ready! To connect to etcd with etcdctl:
|
||||
|
||||
```
|
||||
```shell
|
||||
export ETCDCTL_API=3
|
||||
HOST_1=10.240.0.17
|
||||
HOST_2=10.240.0.18
|
||||
|
|
@ -110,17 +111,17 @@ etcdctl --endpoints=$ENDPOINTS member list
|
|||
|
||||
## Access etcd
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/02_etcdctl_access_etcd_2016051001.gif" alt="02_etcdctl_access_etcd_2016051001"/>
|
||||

|
||||
|
||||
`put` command to write:
|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS put foo "Hello World!"
|
||||
```
|
||||
|
||||
`get` to read from etcd:
|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS get foo
|
||||
etcdctl --endpoints=$ENDPOINTS --write-out="json" get foo
|
||||
```
|
||||
|
|
@ -128,9 +129,9 @@ etcdctl --endpoints=$ENDPOINTS --write-out="json" get foo
|
|||
|
||||
## Get by prefix
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/03_etcdctl_get_by_prefix_2016050501.gif" alt="03_etcdctl_get_by_prefix_2016050501"/>
|
||||

|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS put web1 value1
|
||||
etcdctl --endpoints=$ENDPOINTS put web2 value2
|
||||
etcdctl --endpoints=$ENDPOINTS put web3 value3
|
||||
|
|
@ -141,9 +142,9 @@ etcdctl --endpoints=$ENDPOINTS get web --prefix
|
|||
|
||||
## Delete
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/04_etcdctl_delete_2016050601.gif" alt="04_etcdctl_delete_2016050601"/>
|
||||

|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS put key myvalue
|
||||
etcdctl --endpoints=$ENDPOINTS del key
|
||||
|
||||
|
|
@ -157,9 +158,9 @@ etcdctl --endpoints=$ENDPOINTS del k --prefix
|
|||
|
||||
`txn` to wrap multiple requests into one transaction:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/05_etcdctl_transaction_2016050501.gif" alt="05_etcdctl_transaction_2016050501"/>
|
||||

|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS put user1 bad
|
||||
etcdctl --endpoints=$ENDPOINTS txn --interactive
|
||||
|
||||
|
|
@ -178,9 +179,9 @@ put user1 good
|
|||
|
||||
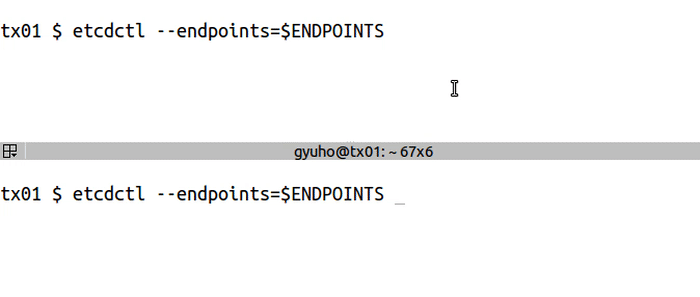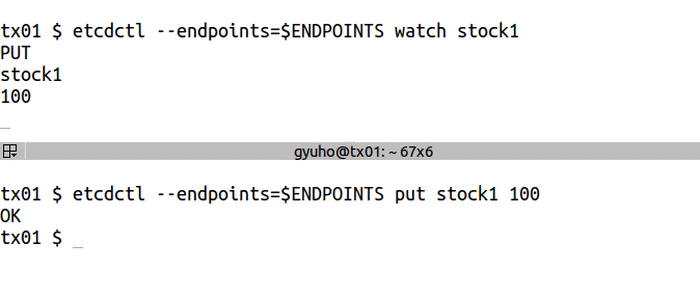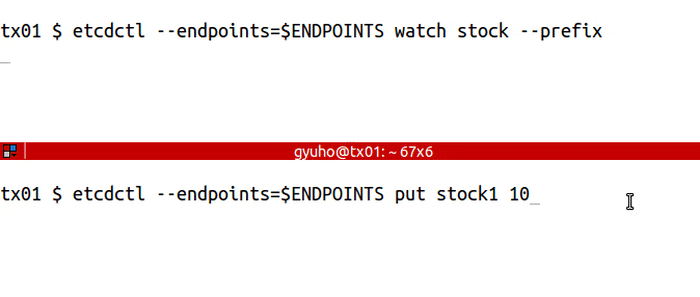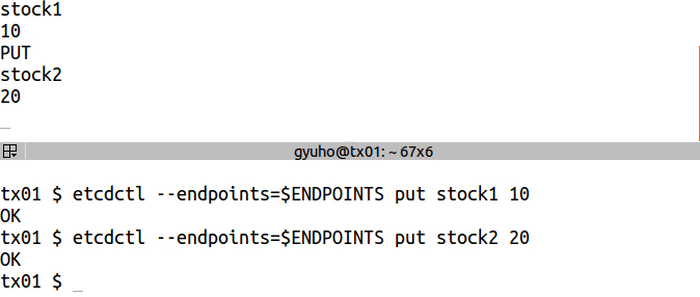
`watch` to get notified of future changes:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/06_etcdctl_watch_2016050501.gif" alt="06_etcdctl_watch_2016050501"/>
|
||||
|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS watch stock1
|
||||
etcdctl --endpoints=$ENDPOINTS put stock1 1000
|
||||
|
||||
|
|
@ -194,9 +195,10 @@ etcdctl --endpoints=$ENDPOINTS put stock2 20
|
|||
|
||||
`lease` to write with TTL:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/07_etcdctl_lease_2016050501.gif" alt="07_etcdctl_lease_2016050501"/>
|
||||
|
||||
```
|
||||

|
||||
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS lease grant 300
|
||||
# lease 2be7547fbc6a5afa granted with TTL(300s)
|
||||
|
||||
|
|
@ -214,9 +216,9 @@ etcdctl --endpoints=$ENDPOINTS get sample
|
|||
|
||||
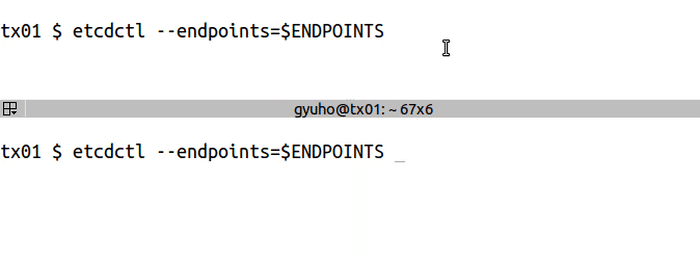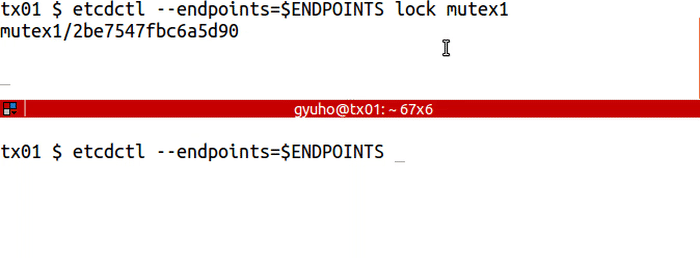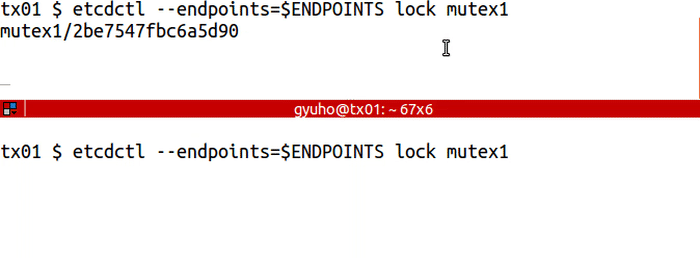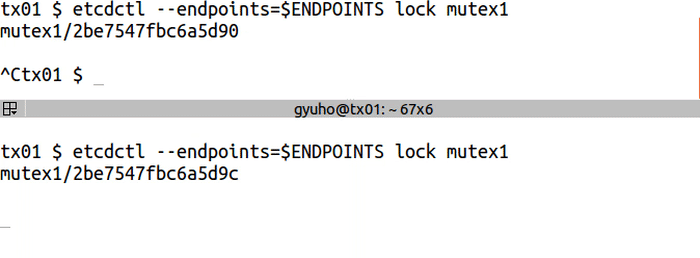
`lock` for distributed lock:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/08_etcdctl_lock_2016050501.gif" alt="08_etcdctl_lock_2016050501"/>
|
||||
|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS lock mutex1
|
||||
|
||||
# another client with the same name blocks
|
||||
|
|
@ -228,9 +230,9 @@ etcdctl --endpoints=$ENDPOINTS lock mutex1
|
|||
|
||||
`elect` for leader election:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/09_etcdctl_elect_2016050501.gif" alt="09_etcdctl_elect_2016050501"/>
|
||||
|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS elect one p1
|
||||
|
||||
# another client with the same name blocks
|
||||
|
|
@ -242,9 +244,9 @@ etcdctl --endpoints=$ENDPOINTS elect one p2
|
|||
|
||||
Specify the initial cluster configuration for each machine:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/10_etcdctl_endpoint_2016050501.gif" alt="10_etcdctl_endpoint_2016050501"/>
|
||||

|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --write-out=table --endpoints=$ENDPOINTS endpoint status
|
||||
|
||||
+------------------+------------------+---------+---------+-----------+-----------+------------+
|
||||
|
|
@ -256,7 +258,7 @@ etcdctl --write-out=table --endpoints=$ENDPOINTS endpoint status
|
|||
+------------------+------------------+---------+---------+-----------+-----------+------------+
|
||||
```
|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --endpoints=$ENDPOINTS endpoint health
|
||||
|
||||
10.240.0.17:2379 is healthy: successfully committed proposal: took = 3.345431ms
|
||||
|
|
@ -269,18 +271,18 @@ etcdctl --endpoints=$ENDPOINTS endpoint health
|
|||
|
||||
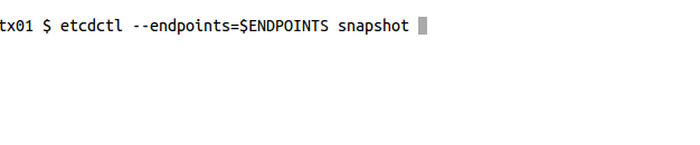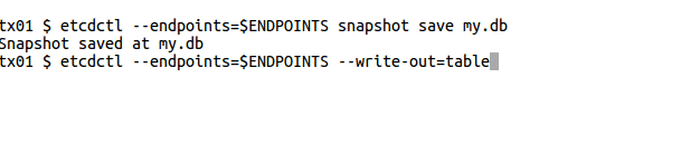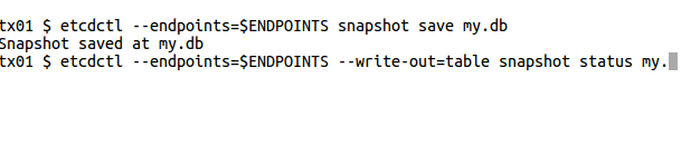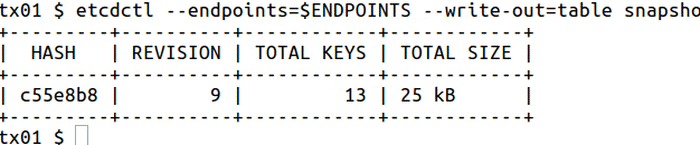
`snapshot` to save point-in-time snapshot of etcd database:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/11_etcdctl_snapshot_2016051001.gif" alt="11_etcdctl_snapshot_2016051001"/>
|
||||
|
||||
|
||||
Snapshot can only be requested from one etcd node, so `--endpoints` flag should contain only one endpoint.
|
||||
|
||||
```
|
||||
```shell
|
||||
ENDPOINTS=$HOST_1:2379
|
||||
etcdctl --endpoints=$ENDPOINTS snapshot save my.db
|
||||
|
||||
Snapshot saved at my.db
|
||||
```
|
||||
|
||||
```
|
||||
```shell
|
||||
etcdctl --write-out=table --endpoints=$ENDPOINTS snapshot status my.db
|
||||
|
||||
+---------+----------+------------+------------+
|
||||
|
|
@ -295,9 +297,10 @@ etcdctl --write-out=table --endpoints=$ENDPOINTS snapshot status my.db
|
|||
|
||||
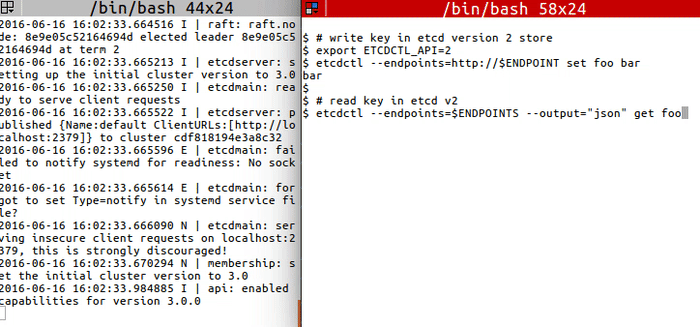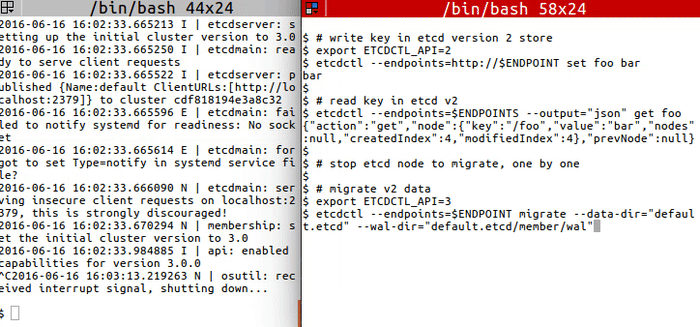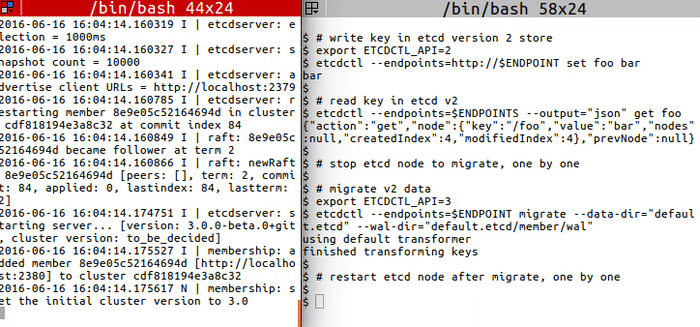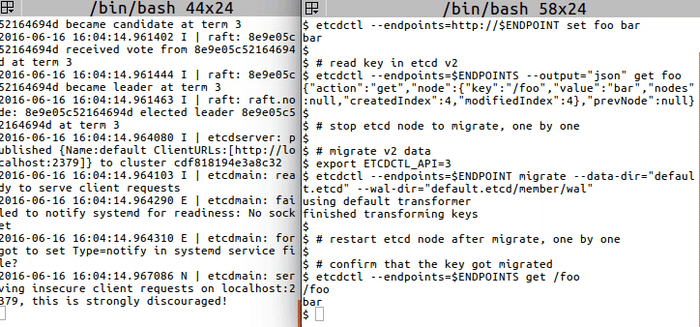
`migrate` to transform etcd v2 to v3 data:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/12_etcdctl_migrate_2016061602.gif" alt="12_etcdctl_migrate_2016061602"/>
|
||||
|
||||
|
||||
```
|
||||
|
||||
```shell
|
||||
# write key in etcd version 2 store
|
||||
export ETCDCTL_API=2
|
||||
etcdctl --endpoints=http://$ENDPOINT set foo bar
|
||||
|
|
@ -322,9 +325,9 @@ etcdctl --endpoints=$ENDPOINTS get /foo
|
|||
|
||||
`member` to add,remove,update membership:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/13_etcdctl_member_2016062301.gif" alt="13_etcdctl_member_2016062301"/>
|
||||

|
||||
|
||||
```
|
||||
```shell
|
||||
# For each machine
|
||||
TOKEN=my-etcd-token-1
|
||||
CLUSTER_STATE=new
|
||||
|
|
@ -375,7 +378,7 @@ etcd --data-dir=data.etcd --name ${THIS_NAME} \
|
|||
|
||||
Then replace a member with `member remove` and `member add` commands:
|
||||
|
||||
```
|
||||
```shell
|
||||
# get member ID
|
||||
export ETCDCTL_API=3
|
||||
HOST_1=10.240.0.13
|
||||
|
|
@ -403,7 +406,7 @@ etcdctl --endpoints=${HOST_1}:2379,${HOST_2}:2379 \
|
|||
|
||||
Next, start the new member with `--initial-cluster-state existing` flag:
|
||||
|
||||
```
|
||||
```shell
|
||||
# [WARNING] If the new member starts from the same disk space,
|
||||
# make sure to remove the data directory of the old member
|
||||
#
|
||||
|
|
@ -435,9 +438,9 @@ etcd --data-dir=data.etcd --name ${THIS_NAME} \
|
|||
|
||||
`auth`,`user`,`role` for authentication:
|
||||
|
||||
<img src="https://storage.googleapis.com/etcd/demo/14_etcdctl_auth_2016062301.gif" alt="14_etcdctl_auth_2016062301"/>
|
||||
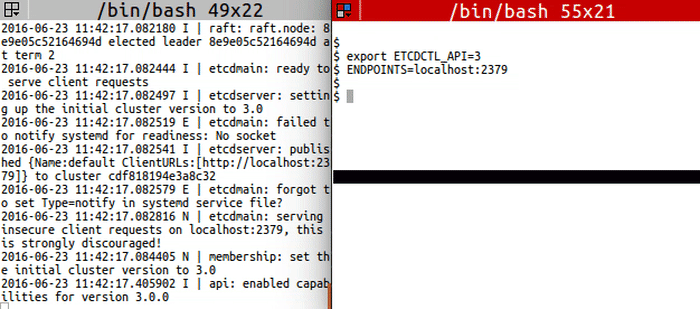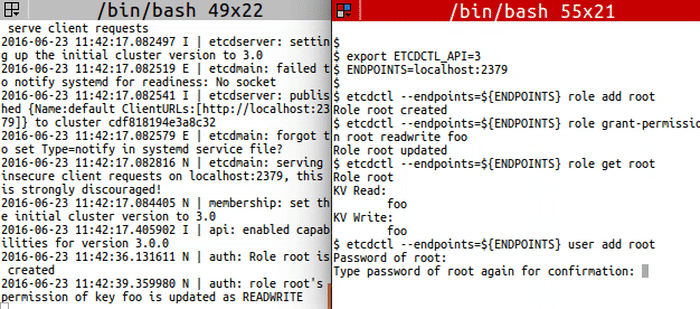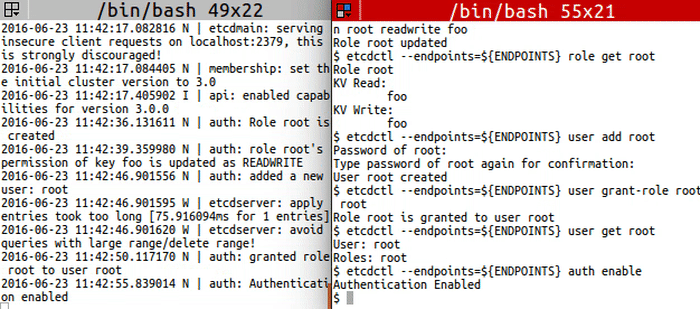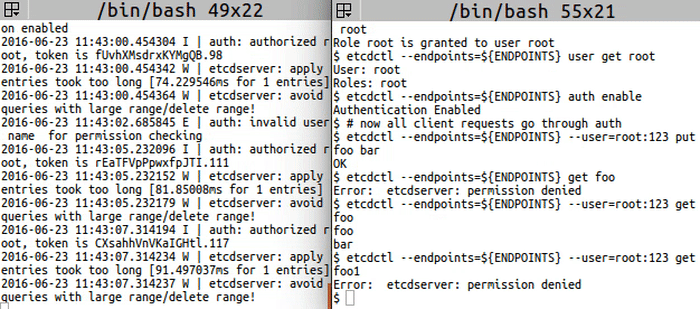
|
||||
|
||||
```
|
||||
```shell
|
||||
export ETCDCTL_API=3
|
||||
ENDPOINTS=localhost:2379
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,3 @@
|
|||
---
|
||||
title: Developer guide
|
||||
---
|
||||
|
|
@ -109,7 +109,7 @@ The status for this discovery token, including the machines that have been regis
|
|||
|
||||
The repository is located at https://github.com/coreos/discovery.etcd.io. It could be used to build a custom discovery service.
|
||||
|
||||
[api]: ../v2/api.md#waiting-for-a-change
|
||||
[cluster-size]: ../v2/admin_guide.md#optimal-cluster-size
|
||||
[api]: /docs/v2/api#waiting-for-a-change
|
||||
[cluster-size]: /docs/v2/admin_guide#optimal-cluster-size
|
||||
[expected-cluster-size]: #specifying-the-expected-cluster-size
|
||||
[new-discovery-token]: #creating-a-new-discovery-token
|
||||
|
|
|
|||
|
|
@ -1,118 +0,0 @@
|
|||
# Documentation
|
||||
|
||||
etcd is a distributed key-value store designed to reliably and quickly preserve and provide access to critical data. It enables reliable distributed coordination through distributed locking, leader elections, and write barriers. An etcd cluster is intended for high availability and permanent data storage and retrieval.
|
||||
|
||||
## Getting started
|
||||
|
||||
New etcd users and developers should get started by [downloading and building][download_build] etcd. After getting etcd, follow this [quick demo][demo] to see the basics of creating and working with an etcd cluster.
|
||||
|
||||
## Developing with etcd
|
||||
|
||||
The easiest way to get started using etcd as a distributed key-value store is to [set up a local cluster][local_cluster].
|
||||
|
||||
- [Setting up local clusters][local_cluster]
|
||||
- [Interacting with etcd][interacting]
|
||||
- gRPC [etcd core][api_ref] and [etcd concurrency][api_concurrency_ref] API references
|
||||
- [HTTP JSON API through the gRPC gateway][api_grpc_gateway]
|
||||
- [gRPC naming and discovery][grpc_naming]
|
||||
- [Client][namespace_client] and [proxy][namespace_proxy] namespacing
|
||||
- [Embedding etcd][embed_etcd]
|
||||
- [Experimental features and APIs][experimental]
|
||||
- [System limits][system-limit]
|
||||
|
||||
## Operating etcd clusters
|
||||
|
||||
Administrators who need a fault-tolerant etcd cluster for either development or production should begin with a [cluster on multiple machines][clustering].
|
||||
|
||||
### Setting up etcd
|
||||
|
||||
- [Configuration flags][conf]
|
||||
- [Multi-member cluster][clustering]
|
||||
- [gRPC proxy][grpc_proxy]
|
||||
- [L4 gateway][gateway]
|
||||
|
||||
### System configuration
|
||||
|
||||
- [Supported systems][supported_platforms]
|
||||
- [Hardware recommendations][hardware]
|
||||
- [Performance benchmarking][performance]
|
||||
- [Tuning][tuning]
|
||||
|
||||
### Platform guides
|
||||
|
||||
- [Amazon Web Services][aws_platform]
|
||||
- [Container Linux, systemd][container_linux_platform]
|
||||
- [FreeBSD][freebsd_platform]
|
||||
- [Docker container][container_docker]
|
||||
- [rkt container][container_rkt]
|
||||
|
||||
### Security
|
||||
|
||||
- [TLS][security]
|
||||
- [Role-based access control][authentication]
|
||||
|
||||
### Maintenance and troubleshooting
|
||||
|
||||
- [Frequently asked questions][faq]
|
||||
- [Monitoring][monitoring]
|
||||
- [Maintenance][maintenance]
|
||||
- [Failure modes][failures]
|
||||
- [Disaster recovery][recovery]
|
||||
- [Upgrading][upgrading]
|
||||
|
||||
## Learning
|
||||
|
||||
To learn more about the concepts and internals behind etcd, read the following pages:
|
||||
|
||||
- [Why etcd?][why]
|
||||
- [Understand data model][data_model]
|
||||
- [Understand APIs][understand_apis]
|
||||
- [Glossary][glossary]
|
||||
- Design
|
||||
- [Auth subsystem][design-auth-v3]
|
||||
- [Client][design-client]
|
||||
- [Learner][design-learner]
|
||||
|
||||
[api_ref]: dev-guide/api_reference_v3.md
|
||||
[api_concurrency_ref]: dev-guide/api_concurrency_reference_v3.md
|
||||
[api_grpc_gateway]: dev-guide/api_grpc_gateway.md
|
||||
[clustering]: op-guide/clustering.md
|
||||
[conf]: op-guide/configuration.md
|
||||
[system-limit]: dev-guide/limit.md
|
||||
[faq]: faq.md
|
||||
[why]: learning/why.md
|
||||
[data_model]: learning/data_model.md
|
||||
[demo]: demo.md
|
||||
[download_build]: dl_build.md
|
||||
[embed_etcd]: https://godoc.org/github.com/etcd-io/etcd/embed
|
||||
[grpc_naming]: dev-guide/grpc_naming.md
|
||||
[failures]: op-guide/failures.md
|
||||
[gateway]: op-guide/gateway.md
|
||||
[glossary]: learning/glossary.md
|
||||
[namespace_client]: https://godoc.org/github.com/etcd-io/etcd/clientv3/namespace
|
||||
[namespace_proxy]: op-guide/grpc_proxy.md#namespacing
|
||||
[grpc_proxy]: op-guide/grpc_proxy.md
|
||||
[hardware]: op-guide/hardware.md
|
||||
[interacting]: dev-guide/interacting_v3.md
|
||||
[local_cluster]: dev-guide/local_cluster.md
|
||||
[performance]: op-guide/performance.md
|
||||
[recovery]: op-guide/recovery.md
|
||||
[maintenance]: op-guide/maintenance.md
|
||||
[security]: op-guide/security.md
|
||||
[monitoring]: op-guide/monitoring.md
|
||||
[v2_migration]: op-guide/v2-migration.md
|
||||
[container_rkt]: op-guide/container.md#rkt
|
||||
[container_docker]: op-guide/container.md#docker
|
||||
[understand_apis]: learning/api.md
|
||||
[versioning]: op-guide/versioning.md
|
||||
[supported_platforms]: op-guide/supported-platform.md
|
||||
[container_linux_platform]: platforms/container-linux-systemd.md
|
||||
[freebsd_platform]: platforms/freebsd.md
|
||||
[aws_platform]: platforms/aws.md
|
||||
[experimental]: dev-guide/experimental_apis.md
|
||||
[authentication]: op-guide/authentication.md
|
||||
[design-auth-v3]: learning/design-auth-v3.md
|
||||
[design-client]: learning/design-client.md
|
||||
[design-learner]: learning/design-learner.md
|
||||
[tuning]: tuning.md
|
||||
[upgrading]: upgrades/upgrading-etcd.md
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
---
|
||||
title: Learning
|
||||
---
|
||||
|
|
@ -110,9 +110,8 @@ The Prometheus client library provides a number of metrics under the `go` and `p
|
|||
|
||||
Heavy file descriptor (`process_open_fds`) usage (i.e., near the process's file descriptor limit, `process_max_fds`) indicates a potential file descriptor exhaustion issue. If the file descriptors are exhausted, etcd may panic because it cannot create new WAL files.
|
||||
|
||||
[glossary-proposal]: learning/glossary.md#proposal
|
||||
[prometheus]: http://prometheus.io/
|
||||
[prometheus-getting-started]: http://prometheus.io/docs/introduction/getting_started/
|
||||
[prometheus-naming]: http://prometheus.io/docs/practices/naming/
|
||||
[v2-http-metrics]: v2/metrics.md#http-requests
|
||||
[go-grpc-prometheus]: https://github.com/grpc-ecosystem/go-grpc-prometheus
|
||||
[prometheus]: https://prometheus.io/
|
||||
[prometheus-getting-started]: https://prometheus.io/docs/introduction/getting_started/
|
||||
[prometheus-naming]: https://prometheus.io/docs/practices/naming/
|
||||
[v2-http-metrics]: /docs/v2/metrics#http-requests
|
||||
[go-grpc-prometheus]: https://github.com/grpc-ecosystem/go-grpc-prometheus
|
||||
|
|
|
|||
|
|
@ -0,0 +1,3 @@
|
|||
---
|
||||
title: Operations guide
|
||||
---
|
||||
|
|
@ -455,13 +455,13 @@ Follow the instructions when using these flags.
|
|||
[reconfig]: runtime-configuration.md
|
||||
[discovery]: clustering.md#discovery
|
||||
[iana-ports]: http://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.txt
|
||||
[proxy]: ../v2/proxy.md
|
||||
[restore]: ../v2/admin_guide.md#restoring-a-backup
|
||||
[security]: security.md
|
||||
[proxy]: /docs/v2/proxy
|
||||
[restore]: /docs/v2/admin_guide#restoring-a-backup
|
||||
[security]: ../security
|
||||
[systemd-intro]: http://freedesktop.org/wiki/Software/systemd/
|
||||
[tuning]: ../tuning.md#time-parameters
|
||||
[sample-config-file]: ../../etcd.conf.yml.sample
|
||||
[recovery]: recovery.md#disaster-recovery
|
||||
[recovery]: ../recovery#disaster-recovery
|
||||
|
||||
### --experimental-peer-skip-client-san-verification
|
||||
+ Skip verification of SAN field in client certificate for peer connections. This can be helpful e.g. if
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ etcd is designed to withstand machine failures. An etcd cluster automatically re
|
|||
|
||||
To recover from disastrous failure, etcd v3 provides snapshot and restore facilities to recreate the cluster without v3 key data loss. To recover v2 keys, refer to the [v2 admin guide][v2_recover].
|
||||
|
||||
[v2_recover]: ../v2/admin_guide.md#disaster-recovery
|
||||
[v2_recover]: /docs/v2/admin_guide#disaster-recovery
|
||||
|
||||
## Snapshotting the keyspace
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,3 @@
|
|||
---
|
||||
title: Platforms
|
||||
---
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
---
|
||||
title: Triage
|
||||
---
|
||||
|
|
@ -1,4 +1,6 @@
|
|||
# Issue Triage Guidelines
|
||||
---
|
||||
title: Issue Triage Guidelines
|
||||
---
|
||||
|
||||
## Purpose
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,3 @@
|
|||
---
|
||||
title: Upgrading
|
||||
---
|
||||
|
|
@ -23,7 +23,7 @@ Following metrics from v3.0.x have been deprecated in favor of [go-grpc-promethe
|
|||
|
||||
#### Upgrade requirements
|
||||
|
||||
To upgrade an existing etcd deployment to 3.1, the running cluster must be 3.0 or greater. If it's before 3.0, please [upgrade to 3.0](upgrade_3_0.md) before upgrading to 3.1.
|
||||
To upgrade an existing etcd deployment to 3.1, the running cluster must be 3.0 or greater. If it's before 3.0, please [upgrade to 3.0](../upgrade_3_0) before upgrading to 3.1.
|
||||
|
||||
Also, to ensure a smooth rolling upgrade, the running cluster must be healthy. Check the health of the cluster by using the `etcdctl endpoint health` command before proceeding.
|
||||
|
||||
|
|
@ -31,7 +31,7 @@ Also, to ensure a smooth rolling upgrade, the running cluster must be healthy. C
|
|||
|
||||
Before upgrading etcd, always test the services relying on etcd in a staging environment before deploying the upgrade to the production environment.
|
||||
|
||||
Before beginning, [backup the etcd data](../op-guide/maintenance.md#snapshot-backup). Should something go wrong with the upgrade, it is possible to use this backup to [downgrade](#downgrade) back to existing etcd version. Please note that the `snapshot` command only backs up the v3 data. For v2 data, see [backing up v2 datastore](../v2/admin_guide.md#backing-up-the-datastore).
|
||||
Before beginning, [backup the etcd data](../op-guide/maintenance#snapshot-backup). Should something go wrong with the upgrade, it is possible to use this backup to [downgrade](#downgrade) back to existing etcd version. Please note that the `snapshot` command only backs up the v3 data. For v2 data, see [backing up v2 datastore](/docs/v2/admin_guide#backing-up-the-datastore).
|
||||
|
||||
#### Mixed versions
|
||||
|
||||
|
|
@ -49,7 +49,7 @@ For a much larger total data size, 100MB or more , this one-time process might t
|
|||
|
||||
If all members have been upgraded to v3.1, the cluster will be upgraded to v3.1, and downgrade from this completed state is **not possible**. If any single member is still v3.0, however, the cluster and its operations remains "v3.0", and it is possible from this mixed cluster state to return to using a v3.0 etcd binary on all members.
|
||||
|
||||
Please [backup the data directory](../op-guide/maintenance.md#snapshot-backup) of all etcd members to make downgrading the cluster possible even after it has been completely upgraded.
|
||||
Please [backup the data directory](../op-guide/maintenance#snapshot-backup) of all etcd members to make downgrading the cluster possible even after it has been completely upgraded.
|
||||
|
||||
### Upgrade procedure
|
||||
|
||||
|
|
@ -82,7 +82,7 @@ When each etcd process is stopped, expected errors will be logged by other clust
|
|||
2017-01-17 09:34:34.364907 W | etcdserver: failed to reach the peerURL(http://localhost:2380) of member fd32987dcd0511e0 (Get http://localhost:2380/version: dial tcp 127.0.0.1:2380: getsockopt: connection refused)
|
||||
```
|
||||
|
||||
It's a good idea at this point to [backup the etcd data](../op-guide/maintenance.md#snapshot-backup) to provide a downgrade path should any problems occur:
|
||||
It's a good idea at this point to [backup the etcd data](../op-guide/maintenance#snapshot-backup) to provide a downgrade path should any problems occur:
|
||||
|
||||
```
|
||||
$ etcdctl snapshot save backup.db
|
||||
|
|
|
|||
|
|
@ -220,7 +220,7 @@ See [issue #6336](https://github.com/etcd-io/etcd/issues/6336) for more contexts
|
|||
|
||||
#### Upgrade requirements
|
||||
|
||||
To upgrade an existing etcd deployment to 3.2, the running cluster must be 3.1 or greater. If it's before 3.1, please [upgrade to 3.1](upgrade_3_1.md) before upgrading to 3.2.
|
||||
To upgrade an existing etcd deployment to 3.2, the running cluster must be 3.1 or greater. If it's before 3.1, please [upgrade to 3.1](../upgrade_3_1) before upgrading to 3.2.
|
||||
|
||||
Also, to ensure a smooth rolling upgrade, the running cluster must be healthy. Check the health of the cluster by using the `etcdctl endpoint health` command before proceeding.
|
||||
|
||||
|
|
@ -228,7 +228,7 @@ Also, to ensure a smooth rolling upgrade, the running cluster must be healthy. C
|
|||
|
||||
Before upgrading etcd, always test the services relying on etcd in a staging environment before deploying the upgrade to the production environment.
|
||||
|
||||
Before beginning, [backup the etcd data](../op-guide/maintenance.md#snapshot-backup). Should something go wrong with the upgrade, it is possible to use this backup to [downgrade](#downgrade) back to existing etcd version. Please note that the `snapshot` command only backs up the v3 data. For v2 data, see [backing up v2 datastore](../v2/admin_guide.md#backing-up-the-datastore).
|
||||
Before beginning, [backup the etcd data](../op-guide/maintenance.md#snapshot-backup). Should something go wrong with the upgrade, it is possible to use this backup to [downgrade](#downgrade) back to existing etcd version. Please note that the `snapshot` command only backs up the v3 data. For v2 data, see [backing up v2 datastore](/docs/v2/admin_guide#backing-up-the-datastore).
|
||||
|
||||
#### Mixed versions
|
||||
|
||||
|
|
|
|||
|
|
@ -1,37 +0,0 @@
|
|||
---
|
||||
title: Snapshot Migration
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
You can migrate a snapshot of your data from a v0.4.9+ cluster into a new etcd 2.2 cluster using a snapshot migration. After snapshot migration, the etcd indexes of your data will change. Many etcd applications rely on these indexes to behave correctly. This operation should only be done while all etcd applications are stopped.
|
||||
|
||||
To get started get the newest data snapshot from the 0.4.9+ cluster:
|
||||
|
||||
```
|
||||
curl http://cluster.example.com:4001/v2/migration/snapshot > backup.snap
|
||||
```
|
||||
|
||||
Now, import the snapshot into your new cluster:
|
||||
|
||||
```
|
||||
etcdctl --endpoint new_cluster.example.com import --snap backup.snap
|
||||
```
|
||||
|
||||
If you have a large amount of data, you can specify more concurrent works to copy data in parallel by using `-c` flag.
|
||||
If you have hidden keys to copy, you can use `--hidden` flag to specify. For example fleet uses `/_coreos.com/fleet` so to import those keys use `--hidden /_coreos.com`.
|
||||
|
||||
And the data will quickly copy into the new cluster:
|
||||
|
||||
```
|
||||
entering dir: /
|
||||
entering dir: /foo
|
||||
entering dir: /foo/bar
|
||||
copying key: /foo/bar/1 1
|
||||
entering dir: /
|
||||
entering dir: /foo2
|
||||
entering dir: /foo2/bar2
|
||||
copying key: /foo2/bar2/2 2
|
||||
```
|
||||
|
|
@ -1,87 +0,0 @@
|
|||
---
|
||||
title: Documentation
|
||||
---
|
||||
|
||||
etcd is a distributed key-value store designed to reliably and quickly preserve and provide access to critical data. It enables reliable distributed coordination through distributed locking, leader elections, and write barriers. An etcd cluster is intended for high availability and permanent data storage and retrieval.
|
||||
|
||||
This is the etcd v2 documentation set. For more recent versions, please see the [etcd v3 guides][etcd-v3].
|
||||
|
||||
## Communicating with etcd v2
|
||||
|
||||
Reading and writing into the etcd keyspace is done via a simple, RESTful HTTP API, or using language-specific libraries that wrap the HTTP API with higher level primitives.
|
||||
|
||||
### Reading and Writing
|
||||
|
||||
- [Client API Documentation][api]
|
||||
- [Libraries, Tools, and Language Bindings][libraries]
|
||||
- [Admin API Documentation][admin-api]
|
||||
- [Members API][members-api]
|
||||
|
||||
### Security, Auth, Access control
|
||||
|
||||
- [Security Model][security]
|
||||
- [Auth and Security][auth_api]
|
||||
- [Authentication Guide][authentication]
|
||||
|
||||
## etcd v2 Cluster Administration
|
||||
|
||||
Configuration values are distributed within the cluster for your applications to read. Values can be changed programmatically and smart applications can reconfigure automatically. You'll never again have to run a configuration management tool on every machine in order to change a single config value.
|
||||
|
||||
### General Info
|
||||
|
||||
- [etcd Proxies][proxy]
|
||||
- [Production Users][production-users]
|
||||
- [Admin Guide][admin_guide]
|
||||
- [Configuration Flags][configuration]
|
||||
- [Frequently Asked Questions][faq]
|
||||
|
||||
### Initial Setup
|
||||
|
||||
- [Tuning etcd Clusters][tuning]
|
||||
- [Discovery Service Protocol][discovery_protocol]
|
||||
- [Running etcd under Docker][docker_guide]
|
||||
|
||||
### Live Reconfiguration
|
||||
|
||||
- [Runtime Configuration][runtime-configuration]
|
||||
|
||||
### Debugging etcd
|
||||
|
||||
- [Metrics Collection][metrics]
|
||||
- [Error Code][errorcode]
|
||||
- [Reporting Bugs][reporting_bugs]
|
||||
|
||||
### Migration
|
||||
|
||||
- [Upgrade etcd to 2.3][upgrade_2_3]
|
||||
- [Upgrade etcd to 2.2][upgrade_2_2]
|
||||
- [Upgrade to etcd 2.1][upgrade_2_1]
|
||||
- [Snapshot Migration (0.4.x to 2.x)][04_to_2_snapshot_migration]
|
||||
- [Backward Compatibility][backward_compatibility]
|
||||
|
||||
|
||||
[etcd-v3]: ../docs.md
|
||||
[api]: api.md
|
||||
[libraries]: libraries-and-tools.md
|
||||
[admin-api]: other_apis.md
|
||||
[members-api]: members_api.md
|
||||
[security]: security.md
|
||||
[auth_api]: auth_api.md
|
||||
[authentication]: authentication.md
|
||||
[proxy]: proxy.md
|
||||
[production-users]: production-users.md
|
||||
[admin_guide]: admin_guide.md
|
||||
[configuration]: configuration.md
|
||||
[faq]: faq.md
|
||||
[tuning]: tuning.md
|
||||
[discovery_protocol]: discovery_protocol.md
|
||||
[docker_guide]: docker_guide.md
|
||||
[runtime-configuration]: runtime-configuration.md
|
||||
[metrics]: metrics.md
|
||||
[errorcode]: errorcode.md
|
||||
[reporting_bugs]: reporting_bugs.md
|
||||
[upgrade_2_3]: upgrade_2_3.md
|
||||
[upgrade_2_2]: upgrade_2_2.md
|
||||
[upgrade_2_1]: upgrade_2_1.md
|
||||
[04_to_2_snapshot_migration]: 04_to_2_snapshot_migration.md
|
||||
[backward_compatibility]: backward_compatibility.md
|
||||
|
|
@ -1,320 +0,0 @@
|
|||
---
|
||||
title: Administration
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
## Data Directory
|
||||
|
||||
### Lifecycle
|
||||
|
||||
When first started, etcd stores its configuration into a data directory specified by the data-dir configuration parameter.
|
||||
Configuration is stored in the write ahead log and includes: the local member ID, cluster ID, and initial cluster configuration.
|
||||
The write ahead log and snapshot files are used during member operation and to recover after a restart.
|
||||
|
||||
Having a dedicated disk to store wal files can improve the throughput and stabilize the cluster.
|
||||
It is highly recommended to dedicate a wal disk and set `--wal-dir` to point to a directory on that device for a production cluster deployment.
|
||||
|
||||
If a member’s data directory is ever lost or corrupted then the user should [remove][remove-a-member] the etcd member from the cluster using `etcdctl` tool.
|
||||
|
||||
A user should avoid restarting an etcd member with a data directory from an out-of-date backup.
|
||||
Using an out-of-date data directory can lead to inconsistency as the member had agreed to store information via raft then re-joins saying it needs that information again.
|
||||
For maximum safety, if an etcd member suffers any sort of data corruption or loss, it must be removed from the cluster.
|
||||
Once removed the member can be re-added with an empty data directory.
|
||||
|
||||
### Contents
|
||||
|
||||
The data directory has two sub-directories in it:
|
||||
|
||||
1. wal: write ahead log files are stored here. For details see the [wal package documentation][wal-pkg]
|
||||
2. snap: log snapshots are stored here. For details see the [snap package documentation][snap-pkg]
|
||||
|
||||
If `--wal-dir` flag is set, etcd will write the write ahead log files to the specified directory instead of data directory.
|
||||
|
||||
## Cluster Management
|
||||
|
||||
### Lifecycle
|
||||
|
||||
If you are spinning up multiple clusters for testing it is recommended that you specify a unique initial-cluster-token for the different clusters.
|
||||
This can protect you from cluster corruption in case of mis-configuration because two members started with different cluster tokens will refuse members from each other.
|
||||
|
||||
### Monitoring
|
||||
|
||||
It is important to monitor your production etcd cluster for healthy information and runtime metrics.
|
||||
|
||||
#### Health Monitoring
|
||||
|
||||
At lowest level, etcd exposes health information via HTTP at `/health` in JSON format. If it returns `{"health":"true"}`, then the cluster is healthy.
|
||||
|
||||
```
|
||||
$ curl -L http://127.0.0.1:2379/health
|
||||
|
||||
{"health":"true"}
|
||||
```
|
||||
|
||||
You can also use etcdctl to check the cluster-wide health information. It will contact all the members of the cluster and collect the health information for you.
|
||||
|
||||
```
|
||||
$./etcdctl cluster-health
|
||||
member 8211f1d0f64f3269 is healthy: got healthy result from http://127.0.0.1:12379
|
||||
member 91bc3c398fb3c146 is healthy: got healthy result from http://127.0.0.1:22379
|
||||
member fd422379fda50e48 is healthy: got healthy result from http://127.0.0.1:32379
|
||||
cluster is healthy
|
||||
```
|
||||
|
||||
#### Runtime Metrics
|
||||
|
||||
etcd uses [Prometheus][prometheus] for metrics reporting in the server. You can read more through the runtime metrics [doc][metrics].
|
||||
|
||||
### Debugging
|
||||
|
||||
Debugging a distributed system can be difficult. etcd provides several ways to make debug
|
||||
easier.
|
||||
|
||||
#### Enabling Debug Logging
|
||||
|
||||
When you want to debug etcd without stopping it, you can enable debug logging at runtime.
|
||||
etcd exposes logging configuration at `/config/local/log`.
|
||||
|
||||
**`/config/local/log` endpoint is being deprecated in v3.5.**
|
||||
|
||||
```
|
||||
$ curl http://127.0.0.1:2379/config/local/log -XPUT -d '{"Level":"DEBUG"}'
|
||||
# debug logging enabled
|
||||
|
||||
$ curl http://127.0.0.1:2379/config/local/log -XPUT -d '{"Level":"INFO"}'
|
||||
# debug logging disabled
|
||||
```
|
||||
|
||||
#### Debugging Variables
|
||||
|
||||
Debug variables are exposed for real-time debugging purposes. Developers who are familiar with etcd can utilize these variables to debug unexpected behavior. etcd exposes debug variables via HTTP at `/debug/vars` in JSON format. The debug variables contains
|
||||
`cmdline`, `file_descriptor_limit`, `memstats` and `raft.status`.
|
||||
|
||||
`cmdline` is the command line arguments passed into etcd.
|
||||
|
||||
`file_descriptor_limit` is the max number of file descriptors etcd can utilize.
|
||||
|
||||
`memstats` is explained in detail in the [Go runtime documentation][golang-memstats].
|
||||
|
||||
`raft.status` is useful when you want to debug low level raft issues if you are familiar with raft internals. In most cases, you do not need to check `raft.status`.
|
||||
|
||||
```json
|
||||
{
|
||||
"cmdline": ["./etcd"],
|
||||
"file_descriptor_limit": 0,
|
||||
"memstats": {"Alloc":4105744,"TotalAlloc":42337320,"Sys":12560632,"...":"..."},
|
||||
"raft.status": {"id":"ce2a822cea30bfca","term":5,"vote":"ce2a822cea30bfca","commit":23509,"lead":"ce2a822cea30bfca","raftState":"StateLeader","progress":{"ce2a822cea30bfca":{"match":23509,"next":23510,"state":"ProgressStateProbe"}}}
|
||||
}
|
||||
```
|
||||
|
||||
### Optimal Cluster Size
|
||||
|
||||
The recommended etcd cluster size is 3, 5 or 7, which is decided by the fault tolerance requirement. A 7-member cluster can provide enough fault tolerance in most cases. While larger cluster provides better fault tolerance the write performance reduces since data needs to be replicated to more machines.
|
||||
|
||||
#### Fault Tolerance Table
|
||||
|
||||
It is recommended to have an odd number of members in a cluster. Having an odd cluster size doesn't change the number needed for majority, but you gain a higher tolerance for failure by adding the extra member. You can see this in practice when comparing even and odd sized clusters:
|
||||
|
||||
| Cluster Size | Majority | Failure Tolerance |
|
||||
|--------------|------------|-------------------|
|
||||
| 1 | 1 | 0 |
|
||||
| 2 | 2 | 0 |
|
||||
| 3 | 2 | **1** |
|
||||
| 4 | 3 | 1 |
|
||||
| 5 | 3 | **2** |
|
||||
| 6 | 4 | 2 |
|
||||
| 7 | 4 | **3** |
|
||||
| 8 | 5 | 3 |
|
||||
| 9 | 5 | **4** |
|
||||
|
||||
As you can see, adding another member to bring the size of cluster up to an odd size is always worth it. During a network partition, an odd number of members also guarantees that there will almost always be a majority of the cluster that can continue to operate and be the source of truth when the partition ends.
|
||||
|
||||
#### Changing Cluster Size
|
||||
|
||||
After your cluster is up and running, adding or removing members is done via [runtime reconfiguration][runtime-reconfig], which allows the cluster to be modified without downtime. The `etcdctl` tool has `member list`, `member add` and `member remove` commands to complete this process.
|
||||
|
||||
### Member Migration
|
||||
|
||||
When there is a scheduled machine maintenance or retirement, you might want to migrate an etcd member to another machine without losing the data and changing the member ID.
|
||||
|
||||
The data directory contains all the data to recover a member to its point-in-time state. To migrate a member:
|
||||
|
||||
* Stop the member process.
|
||||
* Copy the data directory of the now-idle member to the new machine.
|
||||
* Update the peer URLs for the replaced member to reflect the new machine according to the [runtime reconfiguration instructions][update-a-member].
|
||||
* Start etcd on the new machine, using the same configuration and the copy of the data directory.
|
||||
|
||||
This example will walk you through the process of migrating the infra1 member to a new machine:
|
||||
|
||||
|Name|Peer URL|
|
||||
|------|--------------|
|
||||
|infra0|10.0.1.10:2380|
|
||||
|infra1|10.0.1.11:2380|
|
||||
|infra2|10.0.1.12:2380|
|
||||
|
||||
```sh
|
||||
$ export ETCDCTL_ENDPOINT=http://10.0.1.10:2379,http://10.0.1.11:2379,http://10.0.1.12:2379
|
||||
```
|
||||
|
||||
```sh
|
||||
$ etcdctl member list
|
||||
84194f7c5edd8b37: name=infra0 peerURLs=http://10.0.1.10:2380 clientURLs=http://127.0.0.1:2379,http://10.0.1.10:2379
|
||||
b4db3bf5e495e255: name=infra1 peerURLs=http://10.0.1.11:2380 clientURLs=http://127.0.0.1:2379,http://10.0.1.11:2379
|
||||
bc1083c870280d44: name=infra2 peerURLs=http://10.0.1.12:2380 clientURLs=http://127.0.0.1:2379,http://10.0.1.12:2379
|
||||
```
|
||||
|
||||
#### Stop the member etcd process
|
||||
|
||||
```sh
|
||||
$ ssh 10.0.1.11
|
||||
```
|
||||
|
||||
```sh
|
||||
$ kill `pgrep etcd`
|
||||
```
|
||||
|
||||
#### Copy the data directory of the now-idle member to the new machine
|
||||
|
||||
```
|
||||
$ tar -cvzf infra1.etcd.tar.gz %data_dir%
|
||||
```
|
||||
|
||||
```sh
|
||||
$ scp infra1.etcd.tar.gz 10.0.1.13:~/
|
||||
```
|
||||
|
||||
#### Update the peer URLs for that member to reflect the new machine
|
||||
|
||||
```sh
|
||||
$ curl http://10.0.1.10:2379/v2/members/b4db3bf5e495e255 -XPUT \
|
||||
-H "Content-Type: application/json" -d '{"peerURLs":["http://10.0.1.13:2380"]}'
|
||||
```
|
||||
|
||||
Or use `etcdctl member update` command
|
||||
|
||||
```sh
|
||||
$ etcdctl member update b4db3bf5e495e255 http://10.0.1.13:2380
|
||||
```
|
||||
|
||||
#### Start etcd on the new machine, using the same configuration and the copy of the data directory
|
||||
|
||||
```sh
|
||||
$ ssh 10.0.1.13
|
||||
```
|
||||
|
||||
```sh
|
||||
$ tar -xzvf infra1.etcd.tar.gz -C %data_dir%
|
||||
```
|
||||
|
||||
```
|
||||
etcd -name infra1 \
|
||||
-listen-peer-urls http://10.0.1.13:2380 \
|
||||
-listen-client-urls http://10.0.1.13:2379,http://127.0.0.1:2379 \
|
||||
-advertise-client-urls http://10.0.1.13:2379,http://127.0.0.1:2379
|
||||
```
|
||||
|
||||
### Disaster Recovery
|
||||
|
||||
etcd is designed to be resilient to machine failures. An etcd cluster can automatically recover from any number of temporary failures (for example, machine reboots), and a cluster of N members can tolerate up to _(N-1)/2_ permanent failures (where a member can no longer access the cluster, due to hardware failure or disk corruption). However, in extreme circumstances, a cluster might permanently lose enough members such that quorum is irrevocably lost. For example, if a three-node cluster suffered two simultaneous and unrecoverable machine failures, it would be normally impossible for the cluster to restore quorum and continue functioning.
|
||||
|
||||
To recover from such scenarios, etcd provides functionality to backup and restore the datastore and recreate the cluster without data loss.
|
||||
|
||||
#### Backing up the datastore
|
||||
|
||||
**Note:** Windows users must stop etcd before running the backup command.
|
||||
|
||||
The first step of the recovery is to backup the data directory and wal directory, if stored separately, on a functioning etcd node. To do this, use the `etcdctl backup` command, passing in the original data (and wal) directory used by etcd. For example:
|
||||
|
||||
```sh
|
||||
etcdctl backup \
|
||||
--data-dir %data_dir% \
|
||||
[--wal-dir %wal_dir%] \
|
||||
--backup-dir %backup_data_dir%
|
||||
[--backup-wal-dir %backup_wal_dir%]
|
||||
```
|
||||
|
||||
This command will rewrite some of the metadata contained in the backup (specifically, the node ID and cluster ID), which means that the node will lose its former identity. In order to recreate a cluster from the backup, you will need to start a new, single-node cluster. The metadata is rewritten to prevent the new node from inadvertently being joined onto an existing cluster.
|
||||
|
||||
#### Restoring a backup
|
||||
|
||||
To restore a backup using the procedure created above, start etcd with the `--force-new-cluster` option and pointing to the backup directory. This will initialize a new, single-member cluster with the default advertised peer URLs, but preserve the entire contents of the etcd data store. Continuing from the previous example:
|
||||
|
||||
```sh
|
||||
etcd \
|
||||
-data-dir=%backup_data_dir% \
|
||||
[-wal-dir=%backup_wal_dir%] \
|
||||
--force-new-cluster \
|
||||
...
|
||||
```
|
||||
|
||||
Now etcd should be available on this node and serving the original datastore.
|
||||
|
||||
Once you have verified that etcd has started successfully, shut it down and move the data and wal, if stored separately, back to the previous location (you may wish to make another copy as well to be safe):
|
||||
|
||||
```sh
|
||||
pkill etcd
|
||||
rm -fr %data_dir%
|
||||
rm -fr %wal_dir%
|
||||
mv %backup_data_dir% %data_dir%
|
||||
mv %backup_wal_dir% %wal_dir%
|
||||
etcd \
|
||||
-data-dir=%data_dir% \
|
||||
[-wal-dir=%wal_dir%] \
|
||||
...
|
||||
```
|
||||
|
||||
#### Restoring the cluster
|
||||
|
||||
Now that the node is running successfully, [change its advertised peer URLs][update-a-member], as the `--force-new-cluster` option has set the peer URL to the default listening on localhost.
|
||||
|
||||
You can then add more nodes to the cluster and restore resiliency. See the [add a new member][add-a-member] guide for more details.
|
||||
|
||||
**Note:** If you are trying to restore your cluster using old failed etcd nodes, please make sure you have stopped old etcd instances and removed their old data directories specified by the data-dir configuration parameter.
|
||||
|
||||
### Client Request Timeout
|
||||
|
||||
etcd sets different timeouts for various types of client requests. The timeout value is not tunable now, which will be improved soon (https://github.com/etcd-io/etcd/issues/2038).
|
||||
|
||||
#### Get requests
|
||||
|
||||
Timeout is not set for get requests, because etcd serves the result locally in a non-blocking way.
|
||||
|
||||
**Note**: QuorumGet request is a different type, which is mentioned in the following sections.
|
||||
|
||||
#### Watch requests
|
||||
|
||||
Timeout is not set for watch requests. etcd will not stop a watch request until client cancels it, or the connection is broken.
|
||||
|
||||
#### Delete, Put, Post, QuorumGet requests
|
||||
|
||||
The default timeout is 5 seconds. It should be large enough to allow all key modifications if the majority of cluster is functioning.
|
||||
|
||||
If the request times out, it indicates two possibilities:
|
||||
|
||||
1. the server the request sent to was not functioning at that time.
|
||||
2. the majority of the cluster is not functioning.
|
||||
|
||||
If timeout happens several times continuously, administrators should check status of cluster and resolve it as soon as possible.
|
||||
|
||||
### Best Practices
|
||||
|
||||
#### Maximum OS threads
|
||||
|
||||
By default, etcd uses the default configuration of the Go 1.4 runtime, which means that at most one operating system thread will be used to execute code simultaneously. (Note that this default behavior [has changed in Go 1.5][golang1.5-runtime]).
|
||||
|
||||
When using etcd in heavy-load scenarios on machines with multiple cores it will usually be desirable to increase the number of threads that etcd can utilize. To do this, simply set the environment variable GOMAXPROCS to the desired number when starting etcd. For more information on this variable, see the [Go runtime documentation][golang-runtime].
|
||||
|
||||
[add-a-member]: runtime-configuration.md#add-a-new-member
|
||||
[golang1.5-runtime]: https://golang.org/doc/go1.5#runtime
|
||||
[golang-memstats]: https://golang.org/pkg/runtime/#MemStats
|
||||
[golang-runtime]: https://golang.org/pkg/runtime
|
||||
[metrics]: metrics.md
|
||||
[prometheus]: http://prometheus.io/
|
||||
[remove-a-member]: runtime-configuration.md#remove-a-member
|
||||
[runtime-reconfig]: runtime-configuration.md#cluster-reconfiguration-operations
|
||||
[snap-pkg]: http://godoc.org/github.com/coreos/etcd/snap
|
||||
[update-a-member]: runtime-configuration.md#update-a-member
|
||||
[wal-pkg]: http://godoc.org/github.com/coreos/etcd/wal
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -1,98 +0,0 @@
|
|||
---
|
||||
title: etcd3 API
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
TODO: API doc
|
||||
|
||||
## Data Model
|
||||
|
||||
etcd is designed to reliably store infrequently updated data and provide reliable watch queries. etcd exposes previous versions of key-value pairs to support inexpensive snapshots and watch history events (“time travel queries”). A persistent, multi-version, concurrency-control data model is a good fit for these use cases.
|
||||
|
||||
etcd stores data in a multiversion [persistent][persistent-ds] key-value store. The persistent key-value store preserves the previous version of a key-value pair when its value is superseded with new data. The key-value store is effectively immutable; its operations do not update the structure in-place, but instead always generates a new updated structure. All past versions of keys are still accessible and watchable after modification. To prevent the data store from growing indefinitely over time from maintaining old versions, the store may be compacted to shed the oldest versions of superseded data.
|
||||
|
||||
### Logical View
|
||||
|
||||
The store’s logical view is a flat binary key space. The key space has a lexically sorted index on byte string keys so range queries are inexpensive.
|
||||
|
||||
The key space maintains multiple revisions. Each atomic mutative operation (e.g., a transaction operation may contain multiple operations) creates a new revision on the key space. All data held by previous revisions remains unchanged. Old versions of key can still be accessed through previous revisions. Likewise, revisions are indexed as well; ranging over revisions with watchers is efficient. If the store is compacted to recover space, revisions before the compact revision will be removed.
|
||||
|
||||
A key’s lifetime spans a generation. Each key may have one or multiple generations. Creating a key increments the generation of that key, starting at 1 if the key never existed. Deleting a key generates a key tombstone, concluding the key’s current generation. Each modification of a key creates a new version of the key. Once a compaction happens, any generation ended before the given revision will be removed and values set before the compaction revision except the latest one will be removed.
|
||||
|
||||
### Physical View
|
||||
|
||||
etcd stores the physical data as key-value pairs in a persistent [b+tree][b+tree]. Each revision of the store’s state only contains the delta from its previous revision to be efficient. A single revision may correspond to multiple keys in the tree.
|
||||
|
||||
The key of key-value pair is a 3-tuple (major, sub, type). Major is the store revision holding the key. Sub differentiates among keys within the same revision. Type is an optional suffix for special value (e.g., `t` if the value contains a tombstone). The value of the key-value pair contains the modification from previous revision, thus one delta from previous revision. The b+tree is ordered by key in lexical byte-order. Ranged lookups over revision deltas are fast; this enables quickly finding modifications from one specific revision to another. Compaction removes out-of-date keys-value pairs.
|
||||
|
||||
etcd also keeps a secondary in-memory [btree][btree] index to speed up range queries over keys. The keys in the btree index are the keys of the store exposed to user. The value is a pointer to the modification of the persistent b+tree. Compaction removes dead pointers.
|
||||
|
||||
## KV API Guarantees
|
||||
|
||||
etcd is a consistent and durable key value store with mini-transaction(TODO: link to txn doc when we have it) support. The key value store is exposed through the KV APIs. etcd tries to ensure the strongest consistency and durability guarantees for a distributed system. This specification enumerates the KV API guarantees made by etcd.
|
||||
|
||||
### APIs to consider
|
||||
|
||||
* Read APIs
|
||||
* range
|
||||
* watch
|
||||
* Write APIs
|
||||
* put
|
||||
* delete
|
||||
* Combination (read-modify-write) APIs
|
||||
* txn
|
||||
|
||||
### etcd Specific Definitions
|
||||
|
||||
#### operation completed
|
||||
|
||||
An etcd operation is considered complete when it is committed through consensus, and therefore “executed” -- permanently stored -- by the etcd storage engine. The client knows an operation is completed when it receives a response from the etcd server. Note that the client may be uncertain about the status of an operation if it times out, or there is a network disruption between the client and the etcd member. etcd may also abort operations when there is a leader election. etcd does not send `abort` responses to clients’ outstanding requests in this event.
|
||||
|
||||
#### revision
|
||||
|
||||
An etcd operation that modifies the key value store is assigned with a single increasing revision. A transaction operation might modify the key value store multiple times, but only one revision is assigned. The revision attribute of a key value pair that modified by the operation has the same value as the revision of the operation. The revision can be used as a logical clock for key value store. A key value pair that has a larger revision is modified after a key value pair with a smaller revision. Two key value pairs that have the same revision are modified by an operation "concurrently".
|
||||
|
||||
### Guarantees Provided
|
||||
|
||||
#### Atomicity
|
||||
|
||||
All API requests are atomic; an operation either completes entirely or not at all. For watch requests, all events generated by one operation will be in one watch response. Watch never observes partial events for a single operation.
|
||||
|
||||
#### Consistency
|
||||
|
||||
All API calls ensure [sequential consistency][seq_consistency], the strongest consistency guarantee available from distributed systems. No matter which etcd member server a client makes requests to, a client reads the same events in the same order. If two members complete the same number of operations, the state of the two members is consistent.
|
||||
|
||||
For watch operations, etcd guarantees to return the same value for the same key across all members for the same revision. For range operations, etcd has a similar guarantee for [linearized][Linearizability] access; serialized access may be behind the quorum state, so that the later revision is not yet available.
|
||||
|
||||
As with all distributed systems, it is impossible for etcd to ensure [strict consistency][strict_consistency]. etcd does not guarantee that it will return to a read the “most recent” value (as measured by a wall clock when a request is completed) available on any cluster member.
|
||||
|
||||
#### Isolation
|
||||
|
||||
etcd ensures [serializable isolation][serializable_isolation], which is the highest isolation level available in distributed systems. Read operations will never observe any intermediate data.
|
||||
|
||||
#### Durability
|
||||
|
||||
Any completed operations are durable. All accessible data is also durable data. A read will never return data that has not been made durable.
|
||||
|
||||
#### Linearizability
|
||||
|
||||
Linearizability (also known as Atomic Consistency or External Consistency) is a consistency level between strict consistency and sequential consistency.
|
||||
|
||||
For linearizability, suppose each operation receives a timestamp from a loosely synchronized global clock. Operations are linearized if and only if they always complete as though they were executed in a sequential order and each operation appears to complete in the order specified by the program. Likewise, if an operation’s timestamp precedes another, that operation must also precede the other operation in the sequence.
|
||||
|
||||
For example, consider a client completing a write at time point 1 (*t1*). A client issuing a read at *t2* (for *t2* > *t1*) should receive a value at least as recent as the previous write, completed at *t1*. However, the read might actually complete only by *t3*, and the returned value, current at *t2* when the read began, might be "stale" by *t3*.
|
||||
|
||||
etcd does not ensure linearizability for watch operations. Users are expected to verify the revision of watch responses to ensure correct ordering.
|
||||
|
||||
etcd ensures linearizability for all other operations by default. Linearizability comes with a cost, however, because linearized requests must go through the Raft consensus process. To obtain lower latencies and higher throughput for read requests, clients can configure a request’s consistency mode to `serializable`, which may access stale data with respect to quorum, but removes the performance penalty of linearized accesses' reliance on live consensus.
|
||||
|
||||
[persistent-ds]: https://en.wikipedia.org/wiki/Persistent_data_structure
|
||||
[btree]: https://en.wikipedia.org/wiki/B-tree
|
||||
[b+tree]: https://en.wikipedia.org/wiki/B%2B_tree
|
||||
[seq_consistency]: https://en.wikipedia.org/wiki/Consistency_model#Sequential_consistency
|
||||
[strict_consistency]: https://en.wikipedia.org/wiki/Consistency_model#Strict_consistency
|
||||
[serializable_isolation]: https://en.wikipedia.org/wiki/Isolation_(database_systems)#Serializable
|
||||
[Linearizability]: #linearizability
|
||||
|
|
@ -1,517 +0,0 @@
|
|||
---
|
||||
title: v2 Auth and Security
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
## etcd Resources
|
||||
There are three types of resources in etcd
|
||||
|
||||
1. permission resources: users and roles in the user store
|
||||
2. key-value resources: key-value pairs in the key-value store
|
||||
3. settings resources: security settings, auth settings, and dynamic etcd cluster settings (election/heartbeat)
|
||||
|
||||
### Permission Resources
|
||||
|
||||
#### Users
|
||||
A user is an identity to be authenticated. Each user can have multiple roles. The user has a capability (such as reading or writing) on the resource if one of the roles has that capability.
|
||||
|
||||
A user named `root` is required before authentication can be enabled, and it always has the ROOT role. The ROOT role can be granted to multiple users, but `root` is required for recovery purposes.
|
||||
|
||||
#### Roles
|
||||
Each role has exact one associated Permission List. An permission list exists for each permission on key-value resources.
|
||||
|
||||
The special static ROOT (named `root`) role has a full permissions on all key-value resources, the permission to manage user resources and settings resources. Only the ROOT role has the permission to manage user resources and modify settings resources. The ROOT role is built-in and does not need to be created.
|
||||
|
||||
There is also a special GUEST role, named 'guest'. These are the permissions given to unauthenticated requests to etcd. This role will be created automatically, and by default allows access to the full keyspace due to backward compatibility. (etcd did not previously authenticate any actions.). This role can be modified by a ROOT role holder at any time, to reduce the capabilities of unauthenticated users.
|
||||
|
||||
#### Permissions
|
||||
|
||||
There are two types of permissions, `read` and `write`. All management and settings require the ROOT role.
|
||||
|
||||
A Permission List is a list of allowed patterns for that particular permission (read or write). Only ALLOW prefixes are supported. DENY becomes more complicated and is TBD.
|
||||
|
||||
### Key-Value Resources
|
||||
A key-value resource is a key-value pairs in the store. Given a list of matching patterns, permission for any given key in a request is granted if any of the patterns in the list match.
|
||||
|
||||
Only prefixes or exact keys are supported. A prefix permission string ends in `*`.
|
||||
A permission on `/foo` is for that exact key or directory, not its children or recursively. `/foo*` is a prefix that matches `/foo` recursively, and all keys thereunder, and keys with that prefix (eg. `/foobar`. Contrast to the prefix `/foo/*`). `*` alone is permission on the full keyspace.
|
||||
|
||||
### Settings Resources
|
||||
|
||||
Specific settings for the cluster as a whole. This can include adding and removing cluster members, enabling or disabling authentication, replacing certificates, and any other dynamic configuration by the administrator (holder of the ROOT role).
|
||||
|
||||
## v2 Auth
|
||||
|
||||
### Basic Auth
|
||||
We only support [Basic Auth][basic-auth] for the first version. Client needs to attach the basic auth to the HTTP Authorization Header.
|
||||
|
||||
### Authorization field for operations
|
||||
Added to requests to /v2/keys, /v2/auth
|
||||
Add code 401 Unauthorized to the set of responses from the v2 API
|
||||
Authorization: Basic {encoded string}
|
||||
|
||||
### Future Work
|
||||
Other types of auth can be considered for the future (eg, signed certs, public keys) but the `Authorization:` header allows for other such types
|
||||
|
||||
### Things out of Scope for etcd Permissions
|
||||
|
||||
* Pluggable AUTH backends like LDAP (other Authorization tokens generated by LDAP et al may be a possibility)
|
||||
* Very fine-grained access controls (eg: users modifying keys outside work hours)
|
||||
|
||||
|
||||
|
||||
## API endpoints
|
||||
|
||||
An Error JSON corresponds to:
|
||||
{
|
||||
"name": "ErrErrorName",
|
||||
"description" : "The longer helpful description of the error."
|
||||
}
|
||||
|
||||
#### Enable and Disable Authentication
|
||||
|
||||
**Get auth status**
|
||||
|
||||
GET /v2/auth/enable
|
||||
|
||||
Sent Headers:
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
200 Body:
|
||||
{
|
||||
"enabled": true
|
||||
}
|
||||
|
||||
|
||||
**Enable auth**
|
||||
|
||||
PUT /v2/auth/enable
|
||||
|
||||
Sent Headers:
|
||||
Put Body: (empty)
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
400 Bad Request (if root user has not been created)
|
||||
409 Conflict (already enabled)
|
||||
200 Body: (empty)
|
||||
|
||||
**Disable auth**
|
||||
|
||||
DELETE /v2/auth/enable
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <RootAuthString>
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
401 Unauthorized (if not a root user)
|
||||
409 Conflict (already disabled)
|
||||
200 Body: (empty)
|
||||
|
||||
|
||||
#### Users
|
||||
|
||||
The User JSON object is formed as follows:
|
||||
|
||||
```
|
||||
{
|
||||
"user": "userName",
|
||||
"password": "password",
|
||||
"roles": [
|
||||
"role1",
|
||||
"role2"
|
||||
],
|
||||
"grant": [],
|
||||
"revoke": []
|
||||
}
|
||||
```
|
||||
|
||||
Password is only passed when necessary.
|
||||
|
||||
**Get a List of Users**
|
||||
|
||||
GET/HEAD /v2/auth/users
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <BasicAuthString>
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
401 Unauthorized
|
||||
200 Headers:
|
||||
Content-type: application/json
|
||||
200 Body:
|
||||
{
|
||||
"users": [
|
||||
{
|
||||
"user": "alice",
|
||||
"roles": [
|
||||
{
|
||||
"role": "root",
|
||||
"permissions": {
|
||||
"kv": {
|
||||
"read": ["/*"],
|
||||
"write": ["/*"]
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"user": "bob",
|
||||
"roles": [
|
||||
{
|
||||
"role": "guest",
|
||||
"permissions": {
|
||||
"kv": {
|
||||
"read": ["/*"],
|
||||
"write": ["/*"]
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
**Get User Details**
|
||||
|
||||
GET/HEAD /v2/auth/users/alice
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <BasicAuthString>
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
401 Unauthorized
|
||||
404 Not Found
|
||||
200 Headers:
|
||||
Content-type: application/json
|
||||
200 Body:
|
||||
{
|
||||
"user" : "alice",
|
||||
"roles" : [
|
||||
{
|
||||
"role": "fleet",
|
||||
"permissions" : {
|
||||
"kv" : {
|
||||
"read": [ "/fleet/" ],
|
||||
"write": [ "/fleet/" ]
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"role": "etcd",
|
||||
"permissions" : {
|
||||
"kv" : {
|
||||
"read": [ "/*" ],
|
||||
"write": [ "/*" ]
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
**Create Or Update A User**
|
||||
|
||||
A user can be created with initial roles, if filled in. However, no roles are required; only the username and password fields
|
||||
|
||||
PUT /v2/auth/users/charlie
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <BasicAuthString>
|
||||
Put Body:
|
||||
JSON struct, above, matching the appropriate name
|
||||
* Starting password and roles when creating.
|
||||
* Grant/Revoke/Password filled in when updating (to grant roles, revoke roles, or change the password).
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
201 Created
|
||||
400 Bad Request
|
||||
401 Unauthorized
|
||||
404 Not Found (update non-existent users)
|
||||
409 Conflict (when granting duplicated roles or revoking non-existent roles)
|
||||
200 Headers:
|
||||
Content-type: application/json
|
||||
200 Body:
|
||||
JSON state of the user
|
||||
|
||||
**Remove A User**
|
||||
|
||||
DELETE /v2/auth/users/charlie
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <BasicAuthString>
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
401 Unauthorized
|
||||
403 Forbidden (remove root user when auth is enabled)
|
||||
404 Not Found
|
||||
200 Headers:
|
||||
200 Body: (empty)
|
||||
|
||||
#### Roles
|
||||
|
||||
A full role structure may look like this. A Permission List structure is used for the "permissions", "grant", and "revoke" keys.
|
||||
```
|
||||
{
|
||||
"role" : "fleet",
|
||||
"permissions" : {
|
||||
"kv" : {
|
||||
"read" : [ "/fleet/" ],
|
||||
"write": [ "/fleet/" ]
|
||||
}
|
||||
},
|
||||
"grant" : {"kv": {...}},
|
||||
"revoke": {"kv": {...}}
|
||||
}
|
||||
```
|
||||
|
||||
**Get Role Details**
|
||||
|
||||
GET/HEAD /v2/auth/roles/fleet
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <BasicAuthString>
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
401 Unauthorized
|
||||
404 Not Found
|
||||
200 Headers:
|
||||
Content-type: application/json
|
||||
200 Body:
|
||||
{
|
||||
"role" : "fleet",
|
||||
"permissions" : {
|
||||
"kv" : {
|
||||
"read": [ "/fleet/" ],
|
||||
"write": [ "/fleet/" ]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
**Get a list of Roles**
|
||||
|
||||
GET/HEAD /v2/auth/roles
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <BasicAuthString>
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
401 Unauthorized
|
||||
200 Headers:
|
||||
Content-type: application/json
|
||||
200 Body:
|
||||
{
|
||||
"roles": [
|
||||
{
|
||||
"role": "fleet",
|
||||
"permissions": {
|
||||
"kv": {
|
||||
"read": ["/fleet/"],
|
||||
"write": ["/fleet/"]
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"role": "etcd",
|
||||
"permissions": {
|
||||
"kv": {
|
||||
"read": ["/*"],
|
||||
"write": ["/*"]
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"role": "quay",
|
||||
"permissions": {
|
||||
"kv": {
|
||||
"read": ["/*"],
|
||||
"write": ["/*"]
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
**Create Or Update A Role**
|
||||
|
||||
PUT /v2/auth/roles/rkt
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <BasicAuthString>
|
||||
Put Body:
|
||||
Initial desired JSON state, including the role name for verification and:
|
||||
* Starting permission set if creating
|
||||
* Granted/Revoked permission set if updating
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
201 Created
|
||||
400 Bad Request
|
||||
401 Unauthorized
|
||||
404 Not Found (update non-existent roles)
|
||||
409 Conflict (when granting duplicated permission or revoking non-existent permission)
|
||||
200 Body:
|
||||
JSON state of the role
|
||||
|
||||
**Remove A Role**
|
||||
|
||||
DELETE /v2/auth/roles/rkt
|
||||
|
||||
Sent Headers:
|
||||
Authorization: Basic <BasicAuthString>
|
||||
Possible Status Codes:
|
||||
200 OK
|
||||
401 Unauthorized
|
||||
403 Forbidden (remove root)
|
||||
404 Not Found
|
||||
200 Headers:
|
||||
200 Body: (empty)
|
||||
|
||||
|
||||
## Example Workflow
|
||||
|
||||
Let's walk through an example to show two tenants (applications, in our case) using etcd permissions.
|
||||
|
||||
### Create root role
|
||||
|
||||
```
|
||||
PUT /v2/auth/users/root
|
||||
Put Body:
|
||||
{"user" : "root", "password": "betterRootPW!"}
|
||||
```
|
||||
|
||||
### Enable auth
|
||||
|
||||
```
|
||||
PUT /v2/auth/enable
|
||||
```
|
||||
|
||||
### Modify guest role (revoke write permission)
|
||||
|
||||
```
|
||||
PUT /v2/auth/roles/guest
|
||||
Headers:
|
||||
Authorization: Basic <root:betterRootPW!>
|
||||
Put Body:
|
||||
{
|
||||
"role" : "guest",
|
||||
"revoke" : {
|
||||
"kv" : {
|
||||
"write": [
|
||||
"/*"
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Create Roles for the Applications
|
||||
|
||||
Create the rkt role fully specified:
|
||||
|
||||
```
|
||||
PUT /v2/auth/roles/rkt
|
||||
Headers:
|
||||
Authorization: Basic <root:betterRootPW!>
|
||||
Body:
|
||||
{
|
||||
"role" : "rkt",
|
||||
"permissions" : {
|
||||
"kv": {
|
||||
"read": [
|
||||
"/rkt/*"
|
||||
],
|
||||
"write": [
|
||||
"/rkt/*"
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
But let's make fleet just a basic role for now:
|
||||
|
||||
```
|
||||
PUT /v2/auth/roles/fleet
|
||||
Headers:
|
||||
Authorization: Basic <root:betterRootPW!>
|
||||
Body:
|
||||
{
|
||||
"role" : "fleet"
|
||||
}
|
||||
```
|
||||
|
||||
### Optional: Grant some permissions to the roles
|
||||
|
||||
Well, we finally figured out where we want fleet to live. Let's fix it.
|
||||
(Note that we avoided this in the rkt case. So this step is optional.)
|
||||
|
||||
|
||||
```
|
||||
PUT /v2/auth/roles/fleet
|
||||
Headers:
|
||||
Authorization: Basic <root:betterRootPW!>
|
||||
Put Body:
|
||||
{
|
||||
"role" : "fleet",
|
||||
"grant" : {
|
||||
"kv" : {
|
||||
"read": [
|
||||
"/rkt/fleet",
|
||||
"/fleet/*"
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Create Users
|
||||
|
||||
Same as before, let's use rocket all at once and fleet separately
|
||||
|
||||
```
|
||||
PUT /v2/auth/users/rktuser
|
||||
Headers:
|
||||
Authorization: Basic <root:betterRootPW!>
|
||||
Body:
|
||||
{"user" : "rktuser", "password" : "rktpw", "roles" : ["rkt"]}
|
||||
```
|
||||
|
||||
```
|
||||
PUT /v2/auth/users/fleetuser
|
||||
Headers:
|
||||
Authorization: Basic <root:betterRootPW!>
|
||||
Body:
|
||||
{"user" : "fleetuser", "password" : "fleetpw"}
|
||||
```
|
||||
|
||||
### Optional: Grant Roles to Users
|
||||
|
||||
Likewise, let's explicitly grant fleetuser access.
|
||||
|
||||
```
|
||||
PUT /v2/auth/users/fleetuser
|
||||
Headers:
|
||||
Authorization: Basic <root:betterRootPW!>
|
||||
Body:
|
||||
{"user": "fleetuser", "grant": ["fleet"]}
|
||||
```
|
||||
|
||||
#### Start to use fleetuser and rktuser
|
||||
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
PUT /v2/keys/rkt/RktData
|
||||
Headers:
|
||||
Authorization: Basic <rktuser:rktpw>
|
||||
Body:
|
||||
value=launch
|
||||
```
|
||||
|
||||
Reads and writes outside the prefixes granted will fail with a 401 Unauthorized.
|
||||
|
||||
[basic-auth]: https://en.wikipedia.org/wiki/Basic_access_authentication
|
||||
|
|
@ -1,186 +0,0 @@
|
|||
---
|
||||
title: Authentication Guide
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
## Overview
|
||||
|
||||
Authentication -- having users and roles in etcd -- was added in etcd 2.1. This guide will help you set up basic authentication in etcd.
|
||||
|
||||
etcd before 2.1 was a completely open system; anyone with access to the API could change keys. In order to preserve backward compatibility and upgradability, this feature is off by default.
|
||||
|
||||
For a full discussion of the RESTful API, see [the authentication API documentation][auth-api]
|
||||
|
||||
## Special Users and Roles
|
||||
|
||||
There is one special user, `root`, and there are two special roles, `root` and `guest`.
|
||||
|
||||
### User `root`
|
||||
|
||||
User `root` must be created before security can be activated. It has the `root` role and allows for the changing of anything inside etcd. The idea behind the `root` user is for recovery purposes -- a password is generated and stored somewhere -- and the root role is granted to the administrator accounts on the system. In the future, for troubleshooting and recovery, we will need to assume some access to the system, and future documentation will assume this root user (though anyone with the role will suffice).
|
||||
|
||||
### Role `root`
|
||||
|
||||
Role `root` cannot be modified, but it may be granted to any user. Having access via the root role not only allows global read-write access (as was the case before 2.1) but allows modification of the authentication policy and all administrative things, like modifying the cluster membership.
|
||||
|
||||
### Role `guest`
|
||||
|
||||
The `guest` role defines the permissions granted to any request that does not provide an authentication. This will be created on security activation (if it doesn't already exist) to have full access to all keys, as was true in etcd 2.0. It may be modified at any time, and cannot be removed.
|
||||
|
||||
## Working with users
|
||||
|
||||
The `user` subcommand for `etcdctl` handles all things having to do with user accounts.
|
||||
|
||||
A listing of users can be found with
|
||||
|
||||
```
|
||||
$ etcdctl user list
|
||||
```
|
||||
|
||||
Creating a user is as easy as
|
||||
|
||||
```
|
||||
$ etcdctl user add myusername
|
||||
```
|
||||
|
||||
And there will be prompt for a new password.
|
||||
|
||||
Roles can be granted and revoked for a user with
|
||||
|
||||
```
|
||||
$ etcdctl user grant myusername -roles foo,bar,baz
|
||||
$ etcdctl user revoke myusername -roles bar,baz
|
||||
```
|
||||
|
||||
We can look at this user with
|
||||
|
||||
```
|
||||
$ etcdctl user get myusername
|
||||
```
|
||||
|
||||
And the password for a user can be changed with
|
||||
|
||||
```
|
||||
$ etcdctl user passwd myusername
|
||||
```
|
||||
|
||||
Which will prompt again for a new password.
|
||||
|
||||
To delete an account, there's always
|
||||
```
|
||||
$ etcdctl user remove myusername
|
||||
```
|
||||
|
||||
|
||||
## Working with roles
|
||||
|
||||
The `role` subcommand for `etcdctl` handles all things having to do with access controls for particular roles, as were granted to individual users.
|
||||
|
||||
A listing of roles can be found with
|
||||
|
||||
```
|
||||
$ etcdctl role list
|
||||
```
|
||||
|
||||
A new role can be created with
|
||||
|
||||
```
|
||||
$ etcdctl role add myrolename
|
||||
```
|
||||
|
||||
A role has no password; we are merely defining a new set of access rights.
|
||||
|
||||
Roles are granted access to various parts of the keyspace, a single path at a time.
|
||||
|
||||
Reading a path is simple; if the path ends in `*`, that key **and all keys prefixed with it**, are granted to holders of this role. If it does not end in `*`, only that key and that key alone is granted.
|
||||
|
||||
Access can be granted as either read, write, or both, as in the following examples:
|
||||
|
||||
```
|
||||
# Give read access to keys under the /foo directory
|
||||
$ etcdctl role grant myrolename -path '/foo/*' -read
|
||||
|
||||
# Give write-only access to the key at /foo/bar
|
||||
$ etcdctl role grant myrolename -path '/foo/bar' -write
|
||||
|
||||
# Give full access to keys under /pub
|
||||
$ etcdctl role grant myrolename -path '/pub/*' -readwrite
|
||||
```
|
||||
|
||||
Beware that
|
||||
|
||||
```
|
||||
# Give full access to keys under /pub??
|
||||
$ etcdctl role grant myrolename -path '/pub*' -readwrite
|
||||
```
|
||||
|
||||
Without the slash may include keys under `/publishing`, for example. To do both, grant `/pub` and `/pub/*`
|
||||
|
||||
To see what's granted, we can look at the role at any time:
|
||||
|
||||
```
|
||||
$ etcdctl role get myrolename
|
||||
```
|
||||
|
||||
Revocation of permissions is done the same logical way:
|
||||
|
||||
```
|
||||
$ etcdctl role revoke myrolename -path '/foo/bar' -write
|
||||
```
|
||||
|
||||
As is removing a role entirely
|
||||
|
||||
```
|
||||
$ etcdctl role remove myrolename
|
||||
```
|
||||
|
||||
## Enabling authentication
|
||||
|
||||
The minimal steps to enabling auth are as follows. The administrator can set up users and roles before or after enabling authentication, as a matter of preference.
|
||||
|
||||
Make sure the root user is created:
|
||||
|
||||
```
|
||||
$ etcdctl user add root
|
||||
New password:
|
||||
```
|
||||
|
||||
And enable authentication
|
||||
|
||||
```
|
||||
$ etcdctl auth enable
|
||||
```
|
||||
|
||||
After this, etcd is running with authentication enabled. To disable it for any reason, use the reciprocal command:
|
||||
|
||||
```
|
||||
$ etcdctl -u root:rootpw auth disable
|
||||
```
|
||||
|
||||
It would also be good to check what guests (unauthenticated users) are allowed to do:
|
||||
```
|
||||
$ etcdctl -u root:rootpw role get guest
|
||||
```
|
||||
|
||||
And modify this role appropriately, depending on your policies.
|
||||
|
||||
## Using `etcdctl` to authenticate
|
||||
|
||||
`etcdctl` supports a similar flag as `curl` for authentication.
|
||||
|
||||
```
|
||||
$ etcdctl -u user:password get foo
|
||||
```
|
||||
|
||||
or if you prefer to be prompted:
|
||||
|
||||
```
|
||||
$ etcdctl -u user get foo
|
||||
```
|
||||
|
||||
Otherwise, all `etcdctl` commands remain the same. Users and roles can still be created and modified, but require authentication by a user with the root role.
|
||||
|
||||
[auth-api]: auth_api.md
|
||||
|
|
@ -1,78 +0,0 @@
|
|||
---
|
||||
title: Backward Compatibility
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
The main goal of etcd 2.0 release is to improve cluster safety around bootstrapping and dynamic reconfiguration. To do this, we deprecated the old error-prone APIs and provide a new set of APIs.
|
||||
|
||||
The other main focus of this release was a more reliable Raft implementation, but as this change is internal it should not have any notable effects to users.
|
||||
|
||||
## Command Line Flags Changes
|
||||
|
||||
The major flag changes are to mostly related to bootstrapping. The `initial-*` flags provide an improved way to specify the required criteria to start the cluster. The advertised URLs now support a list of values instead of a single value, which allows etcd users to gracefully migrate to the new set of IANA-assigned ports (2379/client and 2380/peers) while maintaining backward compatibility with the old ports.
|
||||
|
||||
- `-addr` is replaced by `-advertise-client-urls`.
|
||||
- `-bind-addr` is replaced by `-listen-client-urls`.
|
||||
- `-peer-addr` is replaced by `-initial-advertise-peer-urls`.
|
||||
- `-peer-bind-addr` is replaced by `-listen-peer-urls`.
|
||||
- `-peers` is replaced by `-initial-cluster`.
|
||||
- `-peers-file` is replaced by `-initial-cluster`.
|
||||
- `-peer-heartbeat-interval` is replaced by `-heartbeat-interval`.
|
||||
- `-peer-election-timeout` is replaced by `-election-timeout`.
|
||||
|
||||
The documentation of new command line flags can be found at
|
||||
https://github.com/etcd-io/etcd/blob/master/Documentation/v2/configuration.md.
|
||||
|
||||
## Data Directory Naming
|
||||
|
||||
The default data dir location has changed from {$hostname}.etcd to {name}.etcd.
|
||||
|
||||
## Key-Value API
|
||||
|
||||
### Read consistency flag
|
||||
|
||||
The consistent flag for read operations is removed in etcd 2.0.0. The normal read operations provides the same consistency guarantees with the 0.4.6 read operations with consistent flag set.
|
||||
|
||||
The read consistency guarantees are:
|
||||
|
||||
The consistent read guarantees the sequential consistency within one client that talks to one etcd server. Read/Write from one client to one etcd member should be observed in order. If one client write a value to an etcd server successfully, it should be able to get the value out of the server immediately.
|
||||
|
||||
Each etcd member will proxy the request to leader and only return the result to user after the result is applied on the local member. Thus after the write succeed, the user is guaranteed to see the value on the member it sent the request to.
|
||||
|
||||
Reads do not provide linearizability. If you want linearizable read, you need to set quorum option to true.
|
||||
|
||||
**Previous behavior**
|
||||
|
||||
We added an option for a consistent read in the old version of etcd since etcd 0.x redirects the write request to the leader. When the user get back the result from the leader, the member it sent the request to originally might not apply the write request yet. With the consistent flag set to true, the client will always send read request to the leader. So one client should be able to see its last write when consistent=true is enabled. There is no order guarantees among different clients.
|
||||
|
||||
|
||||
## Standby
|
||||
|
||||
etcd 0.4’s standby mode has been deprecated. [Proxy mode][proxymode] is introduced to solve a subset of problems standby was solving.
|
||||
|
||||
Standby mode was intended for large clusters that had a subset of the members acting in the consensus process. Overall this process was too magical and allowed for operators to back themselves into a corner.
|
||||
|
||||
Proxy mode in 2.0 will provide similar functionality, and with improved control over which machines act as proxies due to the operator specifically configuring them. Proxies also support read only or read/write modes for increased security and durability.
|
||||
|
||||
[proxymode]: proxy.md
|
||||
|
||||
## Discovery Service
|
||||
|
||||
A size key needs to be provided inside a [discovery token][discoverytoken].
|
||||
|
||||
[discoverytoken]: clustering.md#custom-etcd-discovery-service
|
||||
|
||||
## HTTP Admin API
|
||||
|
||||
`v2/admin` on peer url and `v2/keys/_etcd` are unified under the new [v2/members API][members-api] to better explain which machines are part of an etcd cluster, and to simplify the keyspace for all your use cases.
|
||||
|
||||
[members-api]: members_api.md
|
||||
|
||||
## HTTP Key Value API
|
||||
- The follower can now transparently proxy write requests to the leader. Clients will no longer see 307 redirections to the leader from etcd.
|
||||
|
||||
- Expiration time is in UTC instead of local time.
|
||||
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
# Benchmarks
|
||||
|
||||
etcd benchmarks will be published regularly and tracked for each release below:
|
||||
|
||||
- [etcd v2.1.0-alpha][2.1]
|
||||
- [etcd v2.2.0-rc][2.2]
|
||||
- [etcd v3 demo][3.0]
|
||||
|
||||
# Memory Usage Benchmarks
|
||||
|
||||
It records expected memory usage in different scenarios.
|
||||
|
||||
- [etcd v2.2.0-rc][2.2-mem]
|
||||
|
||||
[2.1]: etcd-2-1-0-alpha-benchmarks.md
|
||||
[2.2]: etcd-2-2-0-rc-benchmarks.md
|
||||
[2.2-mem]: etcd-2-2-0-rc-memory-benchmarks.md
|
||||
[3.0]: etcd-3-demo-benchmarks.md
|
||||
|
|
@ -1,57 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
## Physical machines
|
||||
|
||||
GCE n1-highcpu-2 machine type
|
||||
|
||||
- 1x dedicated local SSD mounted under /var/lib/etcd
|
||||
- 1x dedicated slow disk for the OS
|
||||
- 1.8 GB memory
|
||||
- 2x CPUs
|
||||
- etcd version 2.1.0 alpha
|
||||
|
||||
## etcd Cluster
|
||||
|
||||
3 etcd members, each runs on a single machine
|
||||
|
||||
## Testing
|
||||
|
||||
Bootstrap another machine and use the [boom HTTP benchmark tool][boom] to send requests to each etcd member. Check the [benchmark hacking guide][hack-benchmark] for detailed instructions.
|
||||
|
||||
## Performance
|
||||
|
||||
### reading one single key
|
||||
|
||||
| key size in bytes | number of clients | target etcd server | read QPS | 90th Percentile Latency (ms) |
|
||||
|-------------------|-------------------|--------------------|----------|---------------|
|
||||
| 64 | 1 | leader only | 1534 | 0.7 |
|
||||
| 64 | 64 | leader only | 10125 | 9.1 |
|
||||
| 64 | 256 | leader only | 13892 | 27.1 |
|
||||
| 256 | 1 | leader only | 1530 | 0.8 |
|
||||
| 256 | 64 | leader only | 10106 | 10.1 |
|
||||
| 256 | 256 | leader only | 14667 | 27.0 |
|
||||
| 64 | 64 | all servers | 24200 | 3.9 |
|
||||
| 64 | 256 | all servers | 33300 | 11.8 |
|
||||
| 256 | 64 | all servers | 24800 | 3.9 |
|
||||
| 256 | 256 | all servers | 33000 | 11.5 |
|
||||
|
||||
### writing one single key
|
||||
|
||||
| key size in bytes | number of clients | target etcd server | write QPS | 90th Percentile Latency (ms) |
|
||||
|-------------------|-------------------|--------------------|-----------|---------------|
|
||||
| 64 | 1 | leader only | 60 | 21.4 |
|
||||
| 64 | 64 | leader only | 1742 | 46.8 |
|
||||
| 64 | 256 | leader only | 3982 | 90.5 |
|
||||
| 256 | 1 | leader only | 58 | 20.3 |
|
||||
| 256 | 64 | leader only | 1770 | 47.8 |
|
||||
| 256 | 256 | leader only | 4157 | 105.3 |
|
||||
| 64 | 64 | all servers | 1028 | 123.4 |
|
||||
| 64 | 256 | all servers | 3260 | 123.8 |
|
||||
| 256 | 64 | all servers | 1033 | 121.5 |
|
||||
| 256 | 256 | all servers | 3061 | 119.3 |
|
||||
|
||||
[boom]: https://github.com/rakyll/boom
|
||||
[hack-benchmark]: ../../../hack/benchmark/
|
||||
|
|
@ -1,77 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
# Benchmarking etcd v2.2.0
|
||||
|
||||
## Physical Machines
|
||||
|
||||
GCE n1-highcpu-2 machine type
|
||||
|
||||
- 1x dedicated local SSD mounted as etcd data directory
|
||||
- 1x dedicated slow disk for the OS
|
||||
- 1.8 GB memory
|
||||
- 2x CPUs
|
||||
|
||||
## etcd Cluster
|
||||
|
||||
3 etcd 2.2.0 members, each runs on a single machine.
|
||||
|
||||
Detailed versions:
|
||||
|
||||
```
|
||||
etcd Version: 2.2.0
|
||||
Git SHA: e4561dd
|
||||
Go Version: go1.5
|
||||
Go OS/Arch: linux/amd64
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
Bootstrap another machine, outside of the etcd cluster, and run the [`boom` HTTP benchmark tool][boom] with a connection reuse patch to send requests to each etcd cluster member. See the [benchmark instructions][hack] for the patch and the steps to reproduce our procedures.
|
||||
|
||||
The performance is calculated through results of 100 benchmark rounds.
|
||||
|
||||
## Performance
|
||||
|
||||
### Single Key Read Performance
|
||||
|
||||
| key size in bytes | number of clients | target etcd server | average read QPS | read QPS stddev | average 90th Percentile Latency (ms) | latency stddev |
|
||||
|-------------------|-------------------|--------------------|------------------|-----------------|--------------------------------------|----------------|
|
||||
| 64 | 1 | leader only | 2303 | 200 | 0.49 | 0.06 |
|
||||
| 64 | 64 | leader only | 15048 | 685 | 7.60 | 0.46 |
|
||||
| 64 | 256 | leader only | 14508 | 434 | 29.76 | 1.05 |
|
||||
| 256 | 1 | leader only | 2162 | 214 | 0.52 | 0.06 |
|
||||
| 256 | 64 | leader only | 14789 | 792 | 7.69| 0.48 |
|
||||
| 256 | 256 | leader only | 14424 | 512 | 29.92 | 1.42 |
|
||||
| 64 | 64 | all servers | 45752 | 2048 | 2.47 | 0.14 |
|
||||
| 64 | 256 | all servers | 46592 | 1273 | 10.14 | 0.59 |
|
||||
| 256 | 64 | all servers | 45332 | 1847 | 2.48| 0.12 |
|
||||
| 256 | 256 | all servers | 46485 | 1340 | 10.18 | 0.74 |
|
||||
|
||||
### Single Key Write Performance
|
||||
|
||||
| key size in bytes | number of clients | target etcd server | average write QPS | write QPS stddev | average 90th Percentile Latency (ms) | latency stddev |
|
||||
|-------------------|-------------------|--------------------|------------------|-----------------|--------------------------------------|----------------|
|
||||
| 64 | 1 | leader only | 55 | 4 | 24.51 | 13.26 |
|
||||
| 64 | 64 | leader only | 2139 | 125 | 35.23 | 3.40 |
|
||||
| 64 | 256 | leader only | 4581 | 581 | 70.53 | 10.22 |
|
||||
| 256 | 1 | leader only | 56 | 4 | 22.37| 4.33 |
|
||||
| 256 | 64 | leader only | 2052 | 151 | 36.83 | 4.20 |
|
||||
| 256 | 256 | leader only | 4442 | 560 | 71.59 | 10.03 |
|
||||
| 64 | 64 | all servers | 1625 | 85 | 58.51 | 5.14 |
|
||||
| 64 | 256 | all servers | 4461 | 298 | 89.47 | 36.48 |
|
||||
| 256 | 64 | all servers | 1599 | 94 | 60.11| 6.43 |
|
||||
| 256 | 256 | all servers | 4315 | 193 | 88.98 | 7.01 |
|
||||
|
||||
## Performance Changes
|
||||
|
||||
- Because etcd now records metrics for each API call, read QPS performance seems to see a minor decrease in most scenarios. This minimal performance impact was judged a reasonable investment for the breadth of monitoring and debugging information returned.
|
||||
|
||||
- Write QPS to cluster leaders seems to be increased by a small margin. This is because the main loop and entry apply loops were decoupled in the etcd raft logic, eliminating several blocks between them.
|
||||
|
||||
- Write QPS to all members seems to be increased by a significant margin, because followers now receive the latest commit index sooner, and commit proposals more quickly.
|
||||
|
||||
[boom]: https://github.com/rakyll/boom
|
||||
[hack]: ../../../hack/benchmark/
|
||||
|
|
@ -1,77 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
## Physical machines
|
||||
|
||||
GCE n1-highcpu-2 machine type
|
||||
|
||||
- 1x dedicated local SSD mounted under /var/lib/etcd
|
||||
- 1x dedicated slow disk for the OS
|
||||
- 1.8 GB memory
|
||||
- 2x CPUs
|
||||
|
||||
## etcd Cluster
|
||||
|
||||
3 etcd 2.2.0-rc members, each runs on a single machine.
|
||||
|
||||
Detailed versions:
|
||||
|
||||
```
|
||||
etcd Version: 2.2.0-alpha.1+git
|
||||
Git SHA: 59a5a7e
|
||||
Go Version: go1.4.2
|
||||
Go OS/Arch: linux/amd64
|
||||
```
|
||||
|
||||
Also, we use 3 etcd 2.1.0 alpha-stage members to form cluster to get base performance. etcd's commit head is at [c7146bd5][c7146bd5], which is the same as the one that we use in [etcd 2.1 benchmark][etcd-2.1-benchmark].
|
||||
|
||||
## Testing
|
||||
|
||||
Bootstrap another machine and use the [boom HTTP benchmark tool][boom] to send requests to each etcd member. Check the [benchmark hacking guide][hack-benchmark] for detailed instructions.
|
||||
|
||||
## Performance
|
||||
|
||||
### reading one single key
|
||||
|
||||
| key size in bytes | number of clients | target etcd server | read QPS | 90th Percentile Latency (ms) |
|
||||
|-------------------|-------------------|--------------------|----------|---------------|
|
||||
| 64 | 1 | leader only | 2804 (-5%) | 0.4 (+0%) |
|
||||
| 64 | 64 | leader only | 17816 (+0%) | 5.7 (-6%) |
|
||||
| 64 | 256 | leader only | 18667 (-6%) | 20.4 (+2%) |
|
||||
| 256 | 1 | leader only | 2181 (-15%) | 0.5 (+25%) |
|
||||
| 256 | 64 | leader only | 17435 (-7%) | 6.0 (+9%) |
|
||||
| 256 | 256 | leader only | 18180 (-8%) | 21.3 (+3%) |
|
||||
| 64 | 64 | all servers | 46965 (-4%) | 2.1 (+0%) |
|
||||
| 64 | 256 | all servers | 55286 (-6%) | 7.4 (+6%) |
|
||||
| 256 | 64 | all servers | 46603 (-6%) | 2.1 (+5%) |
|
||||
| 256 | 256 | all servers | 55291 (-6%) | 7.3 (+4%) |
|
||||
|
||||
### writing one single key
|
||||
|
||||
| key size in bytes | number of clients | target etcd server | write QPS | 90th Percentile Latency (ms) |
|
||||
|-------------------|-------------------|--------------------|-----------|---------------|
|
||||
| 64 | 1 | leader only | 76 (+22%) | 19.4 (-15%) |
|
||||
| 64 | 64 | leader only | 2461 (+45%) | 31.8 (-32%) |
|
||||
| 64 | 256 | leader only | 4275 (+1%) | 69.6 (-10%) |
|
||||
| 256 | 1 | leader only | 64 (+20%) | 16.7 (-30%) |
|
||||
| 256 | 64 | leader only | 2385 (+30%) | 31.5 (-19%) |
|
||||
| 256 | 256 | leader only | 4353 (-3%) | 74.0 (+9%) |
|
||||
| 64 | 64 | all servers | 2005 (+81%) | 49.8 (-55%) |
|
||||
| 64 | 256 | all servers | 4868 (+35%) | 81.5 (-40%) |
|
||||
| 256 | 64 | all servers | 1925 (+72%) | 47.7 (-59%) |
|
||||
| 256 | 256 | all servers | 4975 (+36%) | 70.3 (-36%) |
|
||||
|
||||
### performance changes explanation
|
||||
|
||||
- read QPS in most scenarios is decreased by 5~8%. The reason is that etcd records store metrics for each store operation. The metrics is important for monitoring and debugging, so this is acceptable.
|
||||
|
||||
- write QPS to leader is increased by 20~30%. This is because we decouple raft main loop and entry apply loop, which avoids them blocking each other.
|
||||
|
||||
- write QPS to all servers is increased by 30~80% because follower could receive latest commit index earlier and commit proposals faster.
|
||||
|
||||
[boom]: https://github.com/rakyll/boom
|
||||
[c7146bd5]: https://github.com/coreos/etcd/commits/c7146bd5f2c73716091262edc638401bb8229144
|
||||
[etcd-2.1-benchmark]: etcd-2-1-0-alpha-benchmarks.md
|
||||
[hack-benchmark]: ../../../hack/benchmark/
|
||||
|
|
@ -1,52 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
## Physical machine
|
||||
|
||||
GCE n1-standard-2 machine type
|
||||
|
||||
- 1x dedicated local SSD mounted under /var/lib/etcd
|
||||
- 1x dedicated slow disk for the OS
|
||||
- 7.5 GB memory
|
||||
- 2x CPUs
|
||||
|
||||
## etcd
|
||||
|
||||
```
|
||||
etcd Version: 2.2.0-rc.0+git
|
||||
Git SHA: 103cb5c
|
||||
Go Version: go1.5
|
||||
Go OS/Arch: linux/amd64
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
Start 3-member etcd cluster, each of which uses 2 cores.
|
||||
|
||||
The length of key name is always 64 bytes, which is a reasonable length of average key bytes.
|
||||
|
||||
## Memory Maximal Usage
|
||||
|
||||
- etcd may use maximal memory if one follower is dead and the leader keeps sending snapshots.
|
||||
- `max RSS` is the maximal memory usage recorded in 3 runs.
|
||||
|
||||
| value bytes | key number | data size(MB) | max RSS(MB) | max RSS/data rate on leader |
|
||||
|-------------|-------------|---------------|-------------|-----------------------------|
|
||||
| 128 | 50000 | 6 | 433 | 72x |
|
||||
| 128 | 100000 | 12 | 659 | 54x |
|
||||
| 128 | 200000 | 24 | 1466 | 61x |
|
||||
| 1024 | 50000 | 48 | 1253 | 26x |
|
||||
| 1024 | 100000 | 96 | 2344 | 24x |
|
||||
| 1024 | 200000 | 192 | 4361 | 22x |
|
||||
|
||||
## Data Size Threshold
|
||||
|
||||
- When etcd reaches data size threshold, it may trigger leader election easily and drop part of proposals.
|
||||
- At most cases, etcd cluster should work smoothly if it doesn't hit the threshold. If it doesn't work well due to insufficient resources, you need to decrease its data size.
|
||||
|
||||
| value bytes | key number limitation | suggested data size threshold(MB) | consumed RSS(MB) |
|
||||
|-------------|-----------------------|-----------------------------------|------------------|
|
||||
| 128 | 400K | 48 | 2400 |
|
||||
| 1024 | 300K | 292 | 6500 |
|
||||
|
|
@ -1,47 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
## Physical machines
|
||||
|
||||
GCE n1-highcpu-2 machine type
|
||||
|
||||
- 1x dedicated local SSD mounted under /var/lib/etcd
|
||||
- 1x dedicated slow disk for the OS
|
||||
- 1.8 GB memory
|
||||
- 2x CPUs
|
||||
- etcd version 2.2.0
|
||||
|
||||
## etcd Cluster
|
||||
|
||||
1 etcd member running in v3 demo mode
|
||||
|
||||
## Testing
|
||||
|
||||
Use [etcd v3 benchmark tool][etcd-v3-benchmark].
|
||||
|
||||
## Performance
|
||||
|
||||
### reading one single key
|
||||
|
||||
| key size in bytes | number of clients | read QPS | 90th Percentile Latency (ms) |
|
||||
|-------------------|-------------------|----------|---------------|
|
||||
| 256 | 1 | 2716 | 0.4 |
|
||||
| 256 | 64 | 16623 | 6.1 |
|
||||
| 256 | 256 | 16622 | 21.7 |
|
||||
|
||||
The performance is nearly the same as the one with empty server handler.
|
||||
|
||||
### reading one single key after putting
|
||||
|
||||
| key size in bytes | number of clients | read QPS | 90th Percentile Latency (ms) |
|
||||
|-------------------|-------------------|----------|---------------|
|
||||
| 256 | 1 | 2269 | 0.5 |
|
||||
| 256 | 64 | 13582 | 8.6 |
|
||||
| 256 | 256 | 13262 | 47.5 |
|
||||
|
||||
The performance with empty server handler is not affected by one put. So the
|
||||
performance downgrade should be caused by storage package.
|
||||
|
||||
[etcd-v3-benchmark]: ../../../tools/benchmark/
|
||||
|
|
@ -1,82 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
# Watch Memory Usage Benchmark
|
||||
|
||||
*NOTE*: The watch features are under active development, and their memory usage may change as that development progresses. We do not expect it to significantly increase beyond the figures stated below.
|
||||
|
||||
A primary goal of etcd is supporting a very large number of watchers doing a massively large amount of watching. etcd aims to support O(10k) clients, O(100K) watch streams (O(10) streams per client) and O(10M) total watchings (O(100) watching per stream). The memory consumed by each individual watching accounts for the largest portion of etcd's overall usage, and is therefore the focus of current and future optimizations.
|
||||
|
||||
|
||||
Three related components of etcd watch consume physical memory: each `grpc.Conn`, each watch stream, and each instance of the watching activity. `grpc.Conn` maintains the actual TCP connection and other gRPC connection state. Each `grpc.Conn` consumes O(10kb) of memory, and might have multiple watch streams attached.
|
||||
|
||||
Each watch stream is an independent HTTP2 connection which consumes another O(10kb) of memory.
|
||||
Multiple watchings might share one watch stream.
|
||||
|
||||
Watching is the actual struct that tracks the changes on the key-value store. Each watching should only consume < O(1kb).
|
||||
|
||||
```
|
||||
+-------+
|
||||
| watch |
|
||||
+---------> | foo |
|
||||
| +-------+
|
||||
+------+-----+
|
||||
| stream |
|
||||
+--------------> | |
|
||||
| +------+-----+ +-------+
|
||||
| | | watch |
|
||||
| +---------> | bar |
|
||||
+-----+------+ +-------+
|
||||
| | +------------+
|
||||
| conn +-------> | stream |
|
||||
| | | |
|
||||
+-----+------+ +------------+
|
||||
|
|
||||
|
|
||||
|
|
||||
| +------------+
|
||||
+--------------> | stream |
|
||||
| |
|
||||
+------------+
|
||||
```
|
||||
|
||||
The theoretical memory consumption of watch can be approximated with the formula:
|
||||
`memory = c1 * number_of_conn + c2 * avg_number_of_stream_per_conn + c3 * avg_number_of_watch_stream`
|
||||
|
||||
## Testing Environment
|
||||
|
||||
etcd version
|
||||
- git head https://github.com/coreos/etcd/commit/185097ffaa627b909007e772c175e8fefac17af3
|
||||
|
||||
GCE n1-standard-2 machine type
|
||||
- 7.5 GB memory
|
||||
- 2x CPUs
|
||||
|
||||
## Overall memory usage
|
||||
|
||||
The overall memory usage captures how much [RSS][rss] etcd consumes with the client watchers. While the result may vary by as much as 10%, it is still meaningful, since the goal is to learn about the rough memory usage and the pattern of allocations.
|
||||
|
||||
With the benchmark result, we can calculate roughly that `c1 = 17kb`, `c2 = 18kb` and `c3 = 350bytes`. So each additional client connection consumes 17kb of memory and each additional stream consumes 18kb of memory, and each additional watching only cause 350bytes. A single etcd server can maintain millions of watchings with a few GB of memory in normal case.
|
||||
|
||||
|
||||
| clients | streams per client | watchings per stream | total watching | memory usage |
|
||||
|---------|---------|-----------|----------------|--------------|
|
||||
| 1k | 1 | 1 | 1k | 50MB |
|
||||
| 2k | 1 | 1 | 2k | 90MB |
|
||||
| 5k | 1 | 1 | 5k | 200MB |
|
||||
| 1k | 10 | 1 | 10k | 217MB |
|
||||
| 2k | 10 | 1 | 20k | 417MB |
|
||||
| 5k | 10 | 1 | 50k | 980MB |
|
||||
| 1k | 50 | 1 | 50k | 1001MB |
|
||||
| 2k | 50 | 1 | 100k | 1960MB |
|
||||
| 5k | 50 | 1 | 250k | 4700MB |
|
||||
| 1k | 50 | 10 | 500k | 1171MB |
|
||||
| 2k | 50 | 10 | 1M | 2371MB |
|
||||
| 5k | 50 | 10 | 2.5M | 5710MB |
|
||||
| 1k | 50 | 100 | 5M | 2380MB |
|
||||
| 2k | 50 | 100 | 10M | 4672MB |
|
||||
| 5k | 50 | 100 | 50M | *OOM* |
|
||||
|
||||
[rss]: https://en.wikipedia.org/wiki/Resident_set_size
|
||||
|
|
@ -1,103 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
# Storage Memory Usage Benchmark
|
||||
|
||||
<!---todo: link storage to storage design doc-->
|
||||
Two components of etcd storage consume physical memory. The etcd process allocates an *in-memory index* to speed key lookup. The process's *page cache*, managed by the operating system, stores recently-accessed data from disk for quick re-use.
|
||||
|
||||
The in-memory index holds all the keys in a [B-tree][btree] data structure, along with pointers to the on-disk data (the values). Each key in the B-tree may contain multiple pointers, pointing to different versions of its values. The theoretical memory consumption of the in-memory index can hence be approximated with the formula:
|
||||
|
||||
`N * (c1 + avg_key_size) + N * (avg_versions_of_key) * (c2 + size_of_pointer)`
|
||||
|
||||
where `c1` is the key metadata overhead and `c2` is the version metadata overhead.
|
||||
|
||||
The graph shows the detailed structure of the in-memory index B-tree.
|
||||
|
||||
```
|
||||
|
||||
|
||||
In mem index
|
||||
|
||||
+------------+
|
||||
| key || ... |
|
||||
+--------------+ | || |
|
||||
| | +------------+
|
||||
| | | v1 || ... |
|
||||
| disk <----------------| || | Tree Node
|
||||
| | +------------+
|
||||
| | | v2 || ... |
|
||||
| <----------------+ || |
|
||||
| | +------------+
|
||||
+--------------+ +-----+ | | |
|
||||
| | | | |
|
||||
| +------------+
|
||||
|
|
||||
|
|
||||
^
|
||||
------+
|
||||
| ... |
|
||||
| |
|
||||
+-----+
|
||||
| ... | Tree Node
|
||||
| |
|
||||
+-----+
|
||||
| ... |
|
||||
| |
|
||||
------+
|
||||
```
|
||||
|
||||
[Page cache memory][pagecache] is managed by the operating system and is not covered in detail in this document.
|
||||
|
||||
## Testing Environment
|
||||
|
||||
etcd version
|
||||
- git head https://github.com/coreos/etcd/commit/776e9fb7be7eee5e6b58ab977c8887b4fe4d48db
|
||||
|
||||
GCE n1-standard-2 machine type
|
||||
|
||||
- 7.5 GB memory
|
||||
- 2x CPUs
|
||||
|
||||
## In-memory index memory usage
|
||||
|
||||
In this test, we only benchmark the memory usage of the in-memory index. The goal is to find `c1` and `c2` mentioned above and to understand the hard limit of memory consumption of the storage.
|
||||
|
||||
We calculate the memory usage consumption via the Go runtime.ReadMemStats. We calculate the total allocated bytes difference before creating the index and after creating the index. It cannot perfectly reflect the memory usage of the in-memory index itself but can show the rough consumption pattern.
|
||||
|
||||
| N | versions | key size | memory usage |
|
||||
|------|----------|----------|--------------|
|
||||
| 100K | 1 | 64bytes | 22MB |
|
||||
| 100K | 5 | 64bytes | 39MB |
|
||||
| 1M | 1 | 64bytes | 218MB |
|
||||
| 1M | 5 | 64bytes | 432MB |
|
||||
| 100K | 1 | 256bytes | 41MB |
|
||||
| 100K | 5 | 256bytes | 65MB |
|
||||
| 1M | 1 | 256bytes | 409MB |
|
||||
| 1M | 5 | 256bytes | 506MB |
|
||||
|
||||
|
||||
Based on the result, we can calculate `c1=120bytes`, `c2=30bytes`. We only need two sets of data to calculate `c1` and `c2`, since they are the only unknown variable in the formula. The `c1=120bytes` and `c2=30bytes` are the average value of the 4 sets of `c1` and `c2` we calculated. The key metadata overhead is still relatively nontrivial (50%) for small key-value pairs. However, this is a significant improvement over the old store, which had at least 1000% overhead.
|
||||
|
||||
## Overall memory usage
|
||||
|
||||
The overall memory usage captures how much RSS etcd consumes with the storage. The value size should have very little impact on the overall memory usage of etcd, since we keep values on disk and only retain hot values in memory, managed by the OS page cache.
|
||||
|
||||
| N | versions | key size | value size | memory usage |
|
||||
|------|----------|----------|------------|--------------|
|
||||
| 100K | 1 | 64bytes | 256bytes | 40MB |
|
||||
| 100K | 5 | 64bytes | 256bytes | 89MB |
|
||||
| 1M | 1 | 64bytes | 256bytes | 470MB |
|
||||
| 1M | 5 | 64bytes | 256bytes | 880MB |
|
||||
| 100K | 1 | 64bytes | 1KB | 102MB |
|
||||
| 100K | 5 | 64bytes | 1KB | 164MB |
|
||||
| 1M | 1 | 64bytes | 1KB | 587MB |
|
||||
| 1M | 5 | 64bytes | 1KB | 836MB |
|
||||
|
||||
Based on the result, we know the value size does not significantly impact the memory consumption. There is some minor increase due to more data held in the OS page cache.
|
||||
|
||||
[btree]: https://en.wikipedia.org/wiki/B-tree
|
||||
[pagecache]: https://en.wikipedia.org/wiki/Page_cache
|
||||
|
||||
|
|
@ -1,32 +0,0 @@
|
|||
---
|
||||
title: Branch Management
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
## Guide
|
||||
|
||||
* New development occurs on the [master branch][master].
|
||||
* Master branch should always have a green build!
|
||||
* Backwards-compatible bug fixes should target the master branch and subsequently be ported to stable branches.
|
||||
* Once the master branch is ready for release, it will be tagged and become the new stable branch.
|
||||
|
||||
The etcd team has adopted a *rolling release model* and supports one stable version of etcd.
|
||||
|
||||
### Master branch
|
||||
|
||||
The `master` branch is our development branch. All new features land here first.
|
||||
|
||||
If you want to try new features, pull `master` and play with it. Note that `master` may not be stable because new features may introduce bugs.
|
||||
|
||||
Before the release of the next stable version, feature PRs will be frozen. We will focus on the testing, bug-fix and documentation for one to two weeks.
|
||||
|
||||
### Stable branches
|
||||
|
||||
All branches with prefix `release-` are considered _stable_ branches.
|
||||
|
||||
After every minor release (http://semver.org/), we will have a new stable branch for that release. We will keep fixing the backwards-compatible bugs for the latest stable release, but not previous releases. The _patch_ release, incorporating any bug fixes, will be once every two weeks, given any patches.
|
||||
|
||||
[master]: https://github.com/coreos/etcd/tree/master
|
||||
|
|
@ -1,448 +0,0 @@
|
|||
---
|
||||
title: Clustering Guide
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
## Overview
|
||||
|
||||
Starting an etcd cluster statically requires that each member knows another in the cluster. In a number of cases, you might not know the IPs of your cluster members ahead of time. In these cases, you can bootstrap an etcd cluster with the help of a discovery service.
|
||||
|
||||
Once an etcd cluster is up and running, adding or removing members is done via [runtime reconfiguration][runtime-conf]. To better understand the design behind runtime reconfiguration, we suggest you read [the runtime configuration design document][runtime-reconf-design].
|
||||
|
||||
This guide will cover the following mechanisms for bootstrapping an etcd cluster:
|
||||
|
||||
* [Static](#static)
|
||||
* [etcd Discovery](#etcd-discovery)
|
||||
* [DNS Discovery](#dns-discovery)
|
||||
|
||||
Each of the bootstrapping mechanisms will be used to create a three machine etcd cluster with the following details:
|
||||
|
||||
|Name|Address|Hostname|
|
||||
|------|---------|------------------|
|
||||
|infra0|10.0.1.10|infra0.example.com|
|
||||
|infra1|10.0.1.11|infra1.example.com|
|
||||
|infra2|10.0.1.12|infra2.example.com|
|
||||
|
||||
## Static
|
||||
|
||||
As we know the cluster members, their addresses and the size of the cluster before starting, we can use an offline bootstrap configuration by setting the `initial-cluster` flag. Each machine will get either the following command line or environment variables:
|
||||
|
||||
```
|
||||
ETCD_INITIAL_CLUSTER="infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380"
|
||||
ETCD_INITIAL_CLUSTER_STATE=new
|
||||
```
|
||||
|
||||
```
|
||||
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
|
||||
--initial-cluster-state new
|
||||
```
|
||||
|
||||
Note that the URLs specified in `initial-cluster` are the _advertised peer URLs_, i.e. they should match the value of `initial-advertise-peer-urls` on the respective nodes.
|
||||
|
||||
If you are spinning up multiple clusters (or creating and destroying a single cluster) with same configuration for testing purpose, it is highly recommended that you specify a unique `initial-cluster-token` for the different clusters. By doing this, etcd can generate unique cluster IDs and member IDs for the clusters even if they otherwise have the exact same configuration. This can protect you from cross-cluster-interaction, which might corrupt your clusters.
|
||||
|
||||
etcd listens on [`listen-client-urls`][conf-listen-client] to accept client traffic. etcd member advertises the URLs specified in [`advertise-client-urls`][conf-adv-client] to other members, proxies, clients. Please make sure the `advertise-client-urls` are reachable from intended clients. A common mistake is setting `advertise-client-urls` to localhost or leave it as default when you want the remote clients to reach etcd.
|
||||
|
||||
On each machine you would start etcd with these flags:
|
||||
|
||||
```
|
||||
$ etcd --name infra0 --initial-advertise-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-client-urls http://10.0.1.10:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.10:2379 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
|
||||
--initial-cluster-state new
|
||||
```
|
||||
```
|
||||
$ etcd --name infra1 --initial-advertise-peer-urls http://10.0.1.11:2380 \
|
||||
--listen-peer-urls http://10.0.1.11:2380 \
|
||||
--listen-client-urls http://10.0.1.11:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.11:2379 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
|
||||
--initial-cluster-state new
|
||||
```
|
||||
```
|
||||
$ etcd --name infra2 --initial-advertise-peer-urls http://10.0.1.12:2380 \
|
||||
--listen-peer-urls http://10.0.1.12:2380 \
|
||||
--listen-client-urls http://10.0.1.12:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.12:2379 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
|
||||
--initial-cluster-state new
|
||||
```
|
||||
|
||||
The command line parameters starting with `--initial-cluster` will be ignored on subsequent runs of etcd. You are free to remove the environment variables or command line flags after the initial bootstrap process. If you need to make changes to the configuration later (for example, adding or removing members to/from the cluster), see the [runtime configuration][runtime-conf] guide.
|
||||
|
||||
### Error Cases
|
||||
|
||||
In the following example, we have not included our new host in the list of enumerated nodes. If this is a new cluster, the node _must_ be added to the list of initial cluster members.
|
||||
|
||||
```
|
||||
$ etcd --name infra1 --initial-advertise-peer-urls http://10.0.1.11:2380 \
|
||||
--listen-peer-urls https://10.0.1.11:2380 \
|
||||
--listen-client-urls http://10.0.1.11:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.11:2379 \
|
||||
--initial-cluster infra0=http://10.0.1.10:2380 \
|
||||
--initial-cluster-state new
|
||||
etcd: infra1 not listed in the initial cluster config
|
||||
exit 1
|
||||
```
|
||||
|
||||
In this example, we are attempting to map a node (infra0) on a different address (127.0.0.1:2380) than its enumerated address in the cluster list (10.0.1.10:2380). If this node is to listen on multiple addresses, all addresses _must_ be reflected in the "initial-cluster" configuration directive.
|
||||
|
||||
```
|
||||
$ etcd --name infra0 --initial-advertise-peer-urls http://127.0.0.1:2380 \
|
||||
--listen-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-client-urls http://10.0.1.10:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.10:2379 \
|
||||
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
|
||||
--initial-cluster-state=new
|
||||
etcd: error setting up initial cluster: infra0 has different advertised URLs in the cluster and advertised peer URLs list
|
||||
exit 1
|
||||
```
|
||||
|
||||
If you configure a peer with a different set of configuration and attempt to join this cluster you will get a cluster ID mismatch and etcd will exit.
|
||||
|
||||
```
|
||||
$ etcd --name infra3 --initial-advertise-peer-urls http://10.0.1.13:2380 \
|
||||
--listen-peer-urls http://10.0.1.13:2380 \
|
||||
--listen-client-urls http://10.0.1.13:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.13:2379 \
|
||||
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra3=http://10.0.1.13:2380 \
|
||||
--initial-cluster-state=new
|
||||
etcd: conflicting cluster ID to the target cluster (c6ab534d07e8fcc4 != bc25ea2a74fb18b0). Exiting.
|
||||
exit 1
|
||||
```
|
||||
|
||||
## Discovery
|
||||
|
||||
In a number of cases, you might not know the IPs of your cluster peers ahead of time. This is common when utilizing cloud providers or when your network uses DHCP. In these cases, rather than specifying a static configuration, you can use an existing etcd cluster to bootstrap a new one. We call this process "discovery".
|
||||
|
||||
There two methods that can be used for discovery:
|
||||
|
||||
* etcd discovery service
|
||||
* DNS SRV records
|
||||
|
||||
### etcd Discovery
|
||||
|
||||
To better understand the design about discovery service protocol, we suggest you read [this][discovery-proto].
|
||||
|
||||
#### Lifetime of a Discovery URL
|
||||
|
||||
A discovery URL identifies a unique etcd cluster. Instead of reusing a discovery URL, you should always create discovery URLs for new clusters.
|
||||
|
||||
Moreover, discovery URLs should ONLY be used for the initial bootstrapping of a cluster. To change cluster membership after the cluster is already running, see the [runtime reconfiguration][runtime-conf] guide.
|
||||
|
||||
#### Custom etcd Discovery Service
|
||||
|
||||
Discovery uses an existing cluster to bootstrap itself. If you are using your own etcd cluster you can create a URL like so:
|
||||
|
||||
```
|
||||
$ curl -X PUT https://myetcd.local/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83/_config/size -d value=3
|
||||
```
|
||||
|
||||
By setting the size key to the URL, you create a discovery URL with an expected cluster size of 3.
|
||||
|
||||
If you bootstrap an etcd cluster using discovery service with more than the expected number of etcd members, the extra etcd processes will [fall back][fall-back] to being [proxies][proxy] by default.
|
||||
|
||||
The URL you will use in this case will be `https://myetcd.local/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83` and the etcd members will use the `https://myetcd.local/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83` directory for registration as they start.
|
||||
|
||||
**Each member must have a different name flag specified. `Hostname` or `machine-id` can be a good choice. Or discovery will fail due to duplicated name.**
|
||||
|
||||
Now we start etcd with those relevant flags for each member:
|
||||
|
||||
```
|
||||
$ etcd --name infra0 --initial-advertise-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-client-urls http://10.0.1.10:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.10:2379 \
|
||||
--discovery https://myetcd.local/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83
|
||||
```
|
||||
```
|
||||
$ etcd --name infra1 --initial-advertise-peer-urls http://10.0.1.11:2380 \
|
||||
--listen-peer-urls http://10.0.1.11:2380 \
|
||||
--listen-client-urls http://10.0.1.11:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.11:2379 \
|
||||
--discovery https://myetcd.local/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83
|
||||
```
|
||||
```
|
||||
$ etcd --name infra2 --initial-advertise-peer-urls http://10.0.1.12:2380 \
|
||||
--listen-peer-urls http://10.0.1.12:2380 \
|
||||
--listen-client-urls http://10.0.1.12:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.12:2379 \
|
||||
--discovery https://myetcd.local/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83
|
||||
```
|
||||
|
||||
This will cause each member to register itself with the custom etcd discovery service and begin the cluster once all machines have been registered.
|
||||
|
||||
#### Public etcd Discovery Service
|
||||
|
||||
If you do not have access to an existing cluster, you can use the public discovery service hosted at `discovery.etcd.io`. You can create a private discovery URL using the "new" endpoint like so:
|
||||
|
||||
```
|
||||
$ curl https://discovery.etcd.io/new?size=3
|
||||
https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
|
||||
```
|
||||
|
||||
This will create the cluster with an initial expected size of 3 members. If you do not specify a size, a default of 3 will be used.
|
||||
|
||||
If you bootstrap an etcd cluster using discovery service with more than the expected number of etcd members, the extra etcd processes will [fall back][fall-back] to being [proxies][proxy] by default.
|
||||
|
||||
```
|
||||
ETCD_DISCOVERY=https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
|
||||
```
|
||||
|
||||
```
|
||||
-discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
|
||||
```
|
||||
|
||||
**Each member must have a different name flag specified. `Hostname` or `machine-id` can be a good choice. Or discovery will fail due to duplicated name.**
|
||||
|
||||
Now we start etcd with those relevant flags for each member:
|
||||
|
||||
```
|
||||
$ etcd --name infra0 --initial-advertise-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-client-urls http://10.0.1.10:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.10:2379 \
|
||||
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
|
||||
```
|
||||
```
|
||||
$ etcd --name infra1 --initial-advertise-peer-urls http://10.0.1.11:2380 \
|
||||
--listen-peer-urls http://10.0.1.11:2380 \
|
||||
--listen-client-urls http://10.0.1.11:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.11:2379 \
|
||||
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
|
||||
```
|
||||
```
|
||||
$ etcd --name infra2 --initial-advertise-peer-urls http://10.0.1.12:2380 \
|
||||
--listen-peer-urls http://10.0.1.12:2380 \
|
||||
--listen-client-urls http://10.0.1.12:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.12:2379 \
|
||||
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
|
||||
```
|
||||
|
||||
This will cause each member to register itself with the discovery service and begin the cluster once all members have been registered.
|
||||
|
||||
You can use the environment variable `ETCD_DISCOVERY_PROXY` to cause etcd to use an HTTP proxy to connect to the discovery service.
|
||||
|
||||
#### Error and Warning Cases
|
||||
|
||||
##### Discovery Server Errors
|
||||
|
||||
|
||||
```
|
||||
$ etcd --name infra0 --initial-advertise-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-client-urls http://10.0.1.10:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.10:2379 \
|
||||
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
|
||||
etcd: error: the cluster doesn’t have a size configuration value in https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de/_config
|
||||
exit 1
|
||||
```
|
||||
|
||||
##### User Errors
|
||||
|
||||
This error will occur if the discovery cluster already has the configured number of members, and `discovery-fallback` is explicitly disabled
|
||||
|
||||
```
|
||||
$ etcd --name infra0 --initial-advertise-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-client-urls http://10.0.1.10:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.10:2379 \
|
||||
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de \
|
||||
--discovery-fallback exit
|
||||
etcd: discovery: cluster is full
|
||||
exit 1
|
||||
```
|
||||
|
||||
##### Warnings
|
||||
|
||||
This is a harmless warning notifying you that the discovery URL will be
|
||||
ignored on this machine.
|
||||
|
||||
```
|
||||
$ etcd --name infra0 --initial-advertise-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-peer-urls http://10.0.1.10:2380 \
|
||||
--listen-client-urls http://10.0.1.10:2379,http://127.0.0.1:2379 \
|
||||
--advertise-client-urls http://10.0.1.10:2379 \
|
||||
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
|
||||
etcdserver: discovery token ignored since a cluster has already been initialized. Valid log found at /var/lib/etcd
|
||||
```
|
||||
|
||||
### DNS Discovery
|
||||
|
||||
DNS [SRV records][rfc-srv] can be used as a discovery mechanism.
|
||||
The `-discovery-srv` flag can be used to set the DNS domain name where the discovery SRV records can be found.
|
||||
The following DNS SRV records are looked up in the listed order:
|
||||
|
||||
* _etcd-server-ssl._tcp.example.com
|
||||
* _etcd-server._tcp.example.com
|
||||
|
||||
If `_etcd-server-ssl._tcp.example.com` is found then etcd will attempt the bootstrapping process over SSL.
|
||||
|
||||
To help clients discover the etcd cluster, the following DNS SRV records are looked up in the listed order:
|
||||
|
||||
* _etcd-client._tcp.example.com
|
||||
* _etcd-client-ssl._tcp.example.com
|
||||
|
||||
If `_etcd-client-ssl._tcp.example.com` is found, clients will attempt to communicate with the etcd cluster over SSL.
|
||||
|
||||
The `-discovery-srv-name` flag additionally configures a suffix to the SRV name that is queried during discovery.
|
||||
Use this flag to differentiate between multiple etcd clusters under the same domain.
|
||||
For example, if `discovery-srv=example.com` and `-discovery-srv-name=foo` are set, the following DNS SRV queries are made:
|
||||
|
||||
* _etcd-server-ssl-foo._tcp.example.com
|
||||
* _etcd-server-foo._tcp.example.com
|
||||
|
||||
#### Create DNS SRV records
|
||||
|
||||
```
|
||||
$ dig +noall +answer SRV _etcd-server._tcp.example.com
|
||||
_etcd-server._tcp.example.com. 300 IN SRV 0 0 2380 infra0.example.com.
|
||||
_etcd-server._tcp.example.com. 300 IN SRV 0 0 2380 infra1.example.com.
|
||||
_etcd-server._tcp.example.com. 300 IN SRV 0 0 2380 infra2.example.com.
|
||||
```
|
||||
|
||||
```
|
||||
$ dig +noall +answer SRV _etcd-client._tcp.example.com
|
||||
_etcd-client._tcp.example.com. 300 IN SRV 0 0 2379 infra0.example.com.
|
||||
_etcd-client._tcp.example.com. 300 IN SRV 0 0 2379 infra1.example.com.
|
||||
_etcd-client._tcp.example.com. 300 IN SRV 0 0 2379 infra2.example.com.
|
||||
```
|
||||
|
||||
```
|
||||
$ dig +noall +answer infra0.example.com infra1.example.com infra2.example.com
|
||||
infra0.example.com. 300 IN A 10.0.1.10
|
||||
infra1.example.com. 300 IN A 10.0.1.11
|
||||
infra2.example.com. 300 IN A 10.0.1.12
|
||||
```
|
||||
|
||||
#### Bootstrap the etcd cluster using DNS
|
||||
|
||||
etcd cluster members can listen on domain names or IP address, the bootstrap process will resolve DNS A records.
|
||||
|
||||
The resolved address in `--initial-advertise-peer-urls` *must match* one of the resolved addresses in the SRV targets. The etcd member reads the resolved address to find out if it belongs to the cluster defined in the SRV records.
|
||||
|
||||
```
|
||||
$ etcd --name infra0 \
|
||||
--discovery-srv example.com \
|
||||
--initial-advertise-peer-urls http://infra0.example.com:2380 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster-state new \
|
||||
--advertise-client-urls http://infra0.example.com:2379 \
|
||||
--listen-client-urls http://infra0.example.com:2379 \
|
||||
--listen-peer-urls http://infra0.example.com:2380
|
||||
```
|
||||
|
||||
```
|
||||
$ etcd --name infra1 \
|
||||
--discovery-srv example.com \
|
||||
--initial-advertise-peer-urls http://infra1.example.com:2380 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster-state new \
|
||||
--advertise-client-urls http://infra1.example.com:2379 \
|
||||
--listen-client-urls http://infra1.example.com:2379 \
|
||||
--listen-peer-urls http://infra1.example.com:2380
|
||||
```
|
||||
|
||||
```
|
||||
$ etcd --name infra2 \
|
||||
--discovery-srv example.com \
|
||||
--initial-advertise-peer-urls http://infra2.example.com:2380 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster-state new \
|
||||
--advertise-client-urls http://infra2.example.com:2379 \
|
||||
--listen-client-urls http://infra2.example.com:2379 \
|
||||
--listen-peer-urls http://infra2.example.com:2380
|
||||
```
|
||||
|
||||
You can also bootstrap the cluster using IP addresses instead of domain names:
|
||||
|
||||
```
|
||||
$ etcd --name infra0 \
|
||||
--discovery-srv example.com \
|
||||
--initial-advertise-peer-urls http://10.0.1.10:2380 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster-state new \
|
||||
--advertise-client-urls http://10.0.1.10:2379 \
|
||||
--listen-client-urls http://10.0.1.10:2379 \
|
||||
--listen-peer-urls http://10.0.1.10:2380
|
||||
```
|
||||
|
||||
```
|
||||
$ etcd --name infra1 \
|
||||
--discovery-srv example.com \
|
||||
--initial-advertise-peer-urls http://10.0.1.11:2380 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster-state new \
|
||||
--advertise-client-urls http://10.0.1.11:2379 \
|
||||
--listen-client-urls http://10.0.1.11:2379 \
|
||||
--listen-peer-urls http://10.0.1.11:2380
|
||||
```
|
||||
|
||||
```
|
||||
$ etcd --name infra2 \
|
||||
--discovery-srv example.com \
|
||||
--initial-advertise-peer-urls http://10.0.1.12:2380 \
|
||||
--initial-cluster-token etcd-cluster-1 \
|
||||
--initial-cluster-state new \
|
||||
--advertise-client-urls http://10.0.1.12:2379 \
|
||||
--listen-client-urls http://10.0.1.12:2379 \
|
||||
--listen-peer-urls http://10.0.1.12:2380
|
||||
```
|
||||
|
||||
#### etcd proxy configuration
|
||||
|
||||
DNS SRV records can also be used to configure the list of peers for an etcd server running in proxy mode:
|
||||
|
||||
```
|
||||
$ etcd --proxy on --discovery-srv example.com
|
||||
```
|
||||
|
||||
#### etcd client configuration
|
||||
|
||||
DNS SRV records can also be used to help clients discover the etcd cluster.
|
||||
|
||||
The official [etcd/client][client] supports [DNS Discovery][client-discoverer].
|
||||
|
||||
`etcdctl` also supports DNS Discovery by specifying the `--discovery-srv` option.
|
||||
|
||||
```
|
||||
$ etcdctl --discovery-srv example.com set foo bar
|
||||
```
|
||||
|
||||
#### Error Cases
|
||||
|
||||
You might see an error like `cannot find local etcd $name from SRV records.`. That means the etcd member fails to find itself from the cluster defined in SRV records. The resolved address in `--initial-advertise-peer-urls` *must match* one of the resolved addresses in the SRV targets.
|
||||
|
||||
# 0.4 to 2.0+ Migration Guide
|
||||
|
||||
In etcd 2.0 we introduced the ability to listen on more than one address and to advertise multiple addresses. This makes using etcd easier when you have complex networking, such as private and public networks on various cloud providers.
|
||||
|
||||
To make understanding this feature easier, we changed the naming of some flags, but we support the old flags to make the migration from the old to new version easier.
|
||||
|
||||
|Old Flag |New Flag |Migration Behavior |
|
||||
|-----------------------|-----------------------|---------------------------------------------------------------------------------------|
|
||||
|-peer-addr |--initial-advertise-peer-urls |If specified, peer-addr will be used as the only peer URL. Error if both flags specified.|
|
||||
|-addr |--advertise-client-urls |If specified, addr will be used as the only client URL. Error if both flags specified.|
|
||||
|-peer-bind-addr |--listen-peer-urls |If specified, peer-bind-addr will be used as the only peer bind URL. Error if both flags specified.|
|
||||
|-bind-addr |--listen-client-urls |If specified, bind-addr will be used as the only client bind URL. Error if both flags specified.|
|
||||
|-peers |none |Deprecated. The --initial-cluster flag provides a similar concept with different semantics. Please read this guide on cluster startup.|
|
||||
|-peers-file |none |Deprecated. The --initial-cluster flag provides a similar concept with different semantics. Please read this guide on cluster startup.|
|
||||
|
||||
[client]: ../../client
|
||||
[client-discoverer]: https://godoc.org/github.com/coreos/etcd/client#Discoverer
|
||||
[conf-adv-client]: configuration.md#-advertise-client-urls
|
||||
[conf-listen-client]: configuration.md#-listen-client-urls
|
||||
[discovery-proto]: discovery_protocol.md
|
||||
[fall-back]: proxy.md#fallback-to-proxy-mode-with-discovery-service
|
||||
[proxy]: proxy.md
|
||||
[rfc-srv]: http://www.ietf.org/rfc/rfc2052.txt
|
||||
[runtime-conf]: runtime-configuration.md
|
||||
[runtime-reconf-design]: runtime-reconf-design.md
|
||||
|
|
@ -1,299 +0,0 @@
|
|||
---
|
||||
title: Configuration Flags
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
etcd is configurable through command-line flags and environment variables. Options set on the command line take precedence over those from the environment.
|
||||
|
||||
The format of environment variable for flag `--my-flag` is `ETCD_MY_FLAG`. It applies to all flags.
|
||||
|
||||
The [official etcd ports][iana-ports] are 2379 for client requests, and 2380 for peer communication. Some legacy code and documentation still references ports 4001 and 7001, but all new etcd use and discussion should adopt the assigned ports.
|
||||
|
||||
To start etcd automatically using custom settings at startup in Linux, using a [systemd][systemd-intro] unit is highly recommended.
|
||||
|
||||
[systemd-intro]: http://freedesktop.org/wiki/Software/systemd/
|
||||
|
||||
## Member Flags
|
||||
|
||||
### --name
|
||||
+ Human-readable name for this member.
|
||||
+ default: "default"
|
||||
+ env variable: ETCD_NAME
|
||||
+ This value is referenced as this node's own entries listed in the `--initial-cluster` flag (Ex: `default=http://localhost:2380` or `default=http://localhost:2380,default=http://localhost:7001`). This needs to match the key used in the flag if you're using [static bootstrapping][build-cluster]. When using discovery, each member must have a unique name. `Hostname` or `machine-id` can be a good choice.
|
||||
|
||||
### --data-dir
|
||||
+ Path to the data directory.
|
||||
+ default: "${name}.etcd"
|
||||
+ env variable: ETCD_DATA_DIR
|
||||
|
||||
### --wal-dir
|
||||
+ Path to the dedicated wal directory. If this flag is set, etcd will write the WAL files to the walDir rather than the dataDir. This allows a dedicated disk to be used, and helps avoid io competition between logging and other IO operations.
|
||||
+ default: ""
|
||||
+ env variable: ETCD_WAL_DIR
|
||||
|
||||
### --snapshot-count
|
||||
+ Number of committed transactions to trigger a snapshot to disk.
|
||||
+ default: "10000"
|
||||
+ env variable: ETCD_SNAPSHOT_COUNT
|
||||
|
||||
### --heartbeat-interval
|
||||
+ Time (in milliseconds) of a heartbeat interval.
|
||||
+ default: "100"
|
||||
+ env variable: ETCD_HEARTBEAT_INTERVAL
|
||||
|
||||
### --election-timeout
|
||||
+ Time (in milliseconds) for an election to timeout. See [tuning.md](tuning.md#time-parameters) for details.
|
||||
+ default: "1000"
|
||||
+ env variable: ETCD_ELECTION_TIMEOUT
|
||||
|
||||
### --listen-peer-urls
|
||||
+ List of URLs to listen on for peer traffic. This flag tells the etcd to accept incoming requests from its peers on the specified scheme://IP:port combinations. Scheme can be either http or https.If 0.0.0.0 is specified as the IP, etcd listens to the given port on all interfaces. If an IP address is given as well as a port, etcd will listen on the given port and interface. Multiple URLs may be used to specify a number of addresses and ports to listen on. The etcd will respond to requests from any of the listed addresses and ports.
|
||||
+ default: "http://localhost:2380,http://localhost:7001"
|
||||
+ env variable: ETCD_LISTEN_PEER_URLS
|
||||
+ example: "http://10.0.0.1:2380"
|
||||
+ invalid example: "http://example.com:2380" (domain name is invalid for binding)
|
||||
|
||||
### --listen-client-urls
|
||||
+ List of URLs to listen on for client traffic. This flag tells the etcd to accept incoming requests from the clients on the specified scheme://IP:port combinations. Scheme can be either http or https. If 0.0.0.0 is specified as the IP, etcd listens to the given port on all interfaces. If an IP address is given as well as a port, etcd will listen on the given port and interface. Multiple URLs may be used to specify a number of addresses and ports to listen on. The etcd will respond to requests from any of the listed addresses and ports.
|
||||
+ default: "http://localhost:2379,http://localhost:4001"
|
||||
+ env variable: ETCD_LISTEN_CLIENT_URLS
|
||||
+ example: "http://10.0.0.1:2379"
|
||||
+ invalid example: "http://example.com:2379" (domain name is invalid for binding)
|
||||
|
||||
### --max-snapshots
|
||||
+ Maximum number of snapshot files to retain (0 is unlimited)
|
||||
+ default: 5
|
||||
+ env variable: ETCD_MAX_SNAPSHOTS
|
||||
+ The default for users on Windows is unlimited, and manual purging down to 5 (or your preference for safety) is recommended.
|
||||
|
||||
### --max-wals
|
||||
+ Maximum number of wal files to retain (0 is unlimited)
|
||||
+ default: 5
|
||||
+ env variable: ETCD_MAX_WALS
|
||||
+ The default for users on Windows is unlimited, and manual purging down to 5 (or your preference for safety) is recommended.
|
||||
|
||||
### --cors
|
||||
+ Comma-separated white list of origins for CORS (cross-origin resource sharing).
|
||||
+ default: none
|
||||
+ env variable: ETCD_CORS
|
||||
|
||||
## Clustering Flags
|
||||
|
||||
`--initial` prefix flags are used in bootstrapping ([static bootstrap][build-cluster], [discovery-service bootstrap][discovery] or [runtime reconfiguration][reconfig]) a new member, and ignored when restarting an existing member.
|
||||
|
||||
`--discovery` prefix flags need to be set when using [discovery service][discovery].
|
||||
|
||||
### --initial-advertise-peer-urls
|
||||
|
||||
+ List of this member's peer URLs to advertise to the rest of the cluster. These addresses are used for communicating etcd data around the cluster. At least one must be routable to all cluster members. These URLs can contain domain names.
|
||||
+ default: "http://localhost:2380,http://localhost:7001"
|
||||
+ env variable: ETCD_INITIAL_ADVERTISE_PEER_URLS
|
||||
+ example: "http://example.com:2380, http://10.0.0.1:2380"
|
||||
|
||||
### --initial-cluster
|
||||
+ Initial cluster configuration for bootstrapping.
|
||||
+ default: "default=http://localhost:2380,default=http://localhost:7001"
|
||||
+ env variable: ETCD_INITIAL_CLUSTER
|
||||
+ The key is the value of the `--name` flag for each node provided. The default uses `default` for the key because this is the default for the `--name` flag.
|
||||
|
||||
### --initial-cluster-state
|
||||
+ Initial cluster state ("new" or "existing"). Set to `new` for all members present during initial static or DNS bootstrapping. If this option is set to `existing`, etcd will attempt to join the existing cluster. If the wrong value is set, etcd will attempt to start but fail safely.
|
||||
+ default: "new"
|
||||
+ env variable: ETCD_INITIAL_CLUSTER_STATE
|
||||
|
||||
[static bootstrap]: clustering.md#static
|
||||
|
||||
### --initial-cluster-token
|
||||
+ Initial cluster token for the etcd cluster during bootstrap.
|
||||
+ default: "etcd-cluster"
|
||||
+ env variable: ETCD_INITIAL_CLUSTER_TOKEN
|
||||
|
||||
### --advertise-client-urls
|
||||
+ List of this member's client URLs to advertise to the rest of the cluster. These URLs can contain domain names.
|
||||
+ default: "http://localhost:2379,http://localhost:4001"
|
||||
+ env variable: ETCD_ADVERTISE_CLIENT_URLS
|
||||
+ example: "http://example.com:2379, http://10.0.0.1:2379"
|
||||
+ Be careful if you are advertising URLs such as http://localhost:2379 from a cluster member and are using the proxy feature of etcd. This will cause loops, because the proxy will be forwarding requests to itself until its resources (memory, file descriptors) are eventually depleted.
|
||||
|
||||
### --discovery
|
||||
+ Discovery URL used to bootstrap the cluster.
|
||||
+ default: none
|
||||
+ env variable: ETCD_DISCOVERY
|
||||
|
||||
### --discovery-srv
|
||||
+ DNS srv domain used to bootstrap the cluster.
|
||||
+ default: none
|
||||
+ env variable: ETCD_DISCOVERY_SRV
|
||||
|
||||
### --discovery-srv-name
|
||||
+ Suffix to the DNS srv name queried when bootstrapping using DNS.
|
||||
+ default: none
|
||||
+ env variable: ETCD_DISCOVERY_SRV_NAME
|
||||
|
||||
### --discovery-fallback
|
||||
+ Expected behavior ("exit" or "proxy") when discovery services fails.
|
||||
+ default: "proxy"
|
||||
+ env variable: ETCD_DISCOVERY_FALLBACK
|
||||
|
||||
### --discovery-proxy
|
||||
+ HTTP proxy to use for traffic to discovery service.
|
||||
+ default: none
|
||||
+ env variable: ETCD_DISCOVERY_PROXY
|
||||
|
||||
### --strict-reconfig-check
|
||||
+ Reject reconfiguration requests that would cause quorum loss.
|
||||
+ default: false
|
||||
+ env variable: ETCD_STRICT_RECONFIG_CHECK
|
||||
|
||||
## Proxy Flags
|
||||
|
||||
`--proxy` prefix flags configures etcd to run in [proxy mode][proxy].
|
||||
|
||||
### --proxy
|
||||
+ Proxy mode setting ("off", "readonly" or "on").
|
||||
+ default: "off"
|
||||
+ env variable: ETCD_PROXY
|
||||
|
||||
### --proxy-failure-wait
|
||||
+ Time (in milliseconds) an endpoint will be held in a failed state before being reconsidered for proxied requests.
|
||||
+ default: 5000
|
||||
+ env variable: ETCD_PROXY_FAILURE_WAIT
|
||||
|
||||
### --proxy-refresh-interval
|
||||
+ Time (in milliseconds) of the endpoints refresh interval.
|
||||
+ default: 30000
|
||||
+ env variable: ETCD_PROXY_REFRESH_INTERVAL
|
||||
|
||||
### --proxy-dial-timeout
|
||||
+ Time (in milliseconds) for a dial to timeout or 0 to disable the timeout
|
||||
+ default: 1000
|
||||
+ env variable: ETCD_PROXY_DIAL_TIMEOUT
|
||||
|
||||
### --proxy-write-timeout
|
||||
+ Time (in milliseconds) for a write to timeout or 0 to disable the timeout.
|
||||
+ default: 5000
|
||||
+ env variable: ETCD_PROXY_WRITE_TIMEOUT
|
||||
|
||||
### --proxy-read-timeout
|
||||
+ Time (in milliseconds) for a read to timeout or 0 to disable the timeout.
|
||||
+ Don't change this value if you use watches because they are using long polling requests.
|
||||
+ default: 0
|
||||
+ env variable: ETCD_PROXY_READ_TIMEOUT
|
||||
|
||||
## Security Flags
|
||||
|
||||
The security flags help to [build a secure etcd cluster][security].
|
||||
|
||||
### --ca-file
|
||||
|
||||
**DEPRECATED**
|
||||
|
||||
+ Path to the client server TLS CA file. `--ca-file ca.crt` could be replaced by `--trusted-ca-file ca.crt --client-cert-auth` and etcd will perform the same.
|
||||
+ default: none
|
||||
+ env variable: ETCD_CA_FILE
|
||||
|
||||
### --cert-file
|
||||
+ Path to the client server TLS cert file.
|
||||
+ default: none
|
||||
+ env variable: ETCD_CERT_FILE
|
||||
|
||||
### --key-file
|
||||
+ Path to the client server TLS key file.
|
||||
+ default: none
|
||||
+ env variable: ETCD_KEY_FILE
|
||||
|
||||
### --client-cert-auth
|
||||
+ Enable client cert authentication.
|
||||
+ default: false
|
||||
+ env variable: ETCD_CLIENT_CERT_AUTH
|
||||
|
||||
### --trusted-ca-file
|
||||
+ Path to the client server TLS trusted CA cert file.
|
||||
+ default: none
|
||||
+ env variable: ETCD_TRUSTED_CA_FILE
|
||||
|
||||
### --peer-ca-file
|
||||
|
||||
**DEPRECATED**
|
||||
|
||||
+ Path to the peer server TLS CA file. `--peer-ca-file ca.crt` could be replaced by `--peer-trusted-ca-file ca.crt --peer-client-cert-auth` and etcd will perform the same.
|
||||
+ default: none
|
||||
+ env variable: ETCD_PEER_CA_FILE
|
||||
|
||||
### --peer-cert-file
|
||||
+ Path to the peer server TLS cert file.
|
||||
+ default: none
|
||||
+ env variable: ETCD_PEER_CERT_FILE
|
||||
|
||||
### --peer-key-file
|
||||
+ Path to the peer server TLS key file.
|
||||
+ default: none
|
||||
+ env variable: ETCD_PEER_KEY_FILE
|
||||
|
||||
### --peer-client-cert-auth
|
||||
+ Enable peer client cert authentication.
|
||||
+ default: false
|
||||
+ env variable: ETCD_PEER_CLIENT_CERT_AUTH
|
||||
|
||||
### --peer-trusted-ca-file
|
||||
+ Path to the peer server TLS trusted CA file.
|
||||
+ default: none
|
||||
+ env variable: ETCD_PEER_TRUSTED_CA_FILE
|
||||
|
||||
## Logging Flags
|
||||
|
||||
### --debug
|
||||
+ Drop the default log level to DEBUG for all subpackages.
|
||||
+ default: false (INFO for all packages)
|
||||
+ env variable: ETCD_DEBUG
|
||||
|
||||
### --log-package-levels
|
||||
+ Set individual etcd subpackages to specific log levels. An example being `etcdserver=WARNING,security=DEBUG`
|
||||
+ default: none (INFO for all packages)
|
||||
+ env variable: ETCD_LOG_PACKAGE_LEVELS
|
||||
|
||||
|
||||
## Unsafe Flags
|
||||
|
||||
Please be CAUTIOUS when using unsafe flags because it will break the guarantees given by the consensus protocol.
|
||||
For example, it may panic if other members in the cluster are still alive.
|
||||
Follow the instructions when using these flags.
|
||||
|
||||
### --force-new-cluster
|
||||
+ Force to create a new one-member cluster. It commits configuration changes forcing to remove all existing members in the cluster and add itself. It needs to be set to [restore a backup][restore].
|
||||
+ default: false
|
||||
+ env variable: ETCD_FORCE_NEW_CLUSTER
|
||||
|
||||
## Experimental Flags
|
||||
|
||||
### --experimental-v3demo
|
||||
+ Enable experimental [v3 demo API][rfc-v3].
|
||||
+ default: false
|
||||
+ env variable: ETCD_EXPERIMENTAL_V3DEMO
|
||||
|
||||
## Miscellaneous Flags
|
||||
|
||||
### --version
|
||||
+ Print the version and exit.
|
||||
+ default: false
|
||||
|
||||
## Profiling flags
|
||||
|
||||
### --enable-pprof
|
||||
+ Enable runtime profiling data via HTTP server. Address is at client URL + "/debug/pprof/"
|
||||
+ default: false
|
||||
|
||||
[build-cluster]: clustering.md#static
|
||||
[reconfig]: runtime-configuration.md
|
||||
[discovery]: clustering.md#discovery
|
||||
[iana-ports]: http://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.txt
|
||||
[proxy]: proxy.md
|
||||
[reconfig]: runtime-configuration.md
|
||||
[restore]: admin_guide.md#restoring-a-backup
|
||||
[rfc-v3]: rfc/v3api.md
|
||||
[security]: security.md
|
||||
[systemd-intro]: http://freedesktop.org/wiki/Software/systemd/
|
||||
[tuning]: tuning.md#time-parameters
|
||||
|
|
@ -1,112 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
# etcd release guide
|
||||
|
||||
The guide talks about how to release a new version of etcd.
|
||||
|
||||
The procedure includes some manual steps for sanity checking but it can probably be further scripted. Please keep this document up-to-date if you want to make changes to the release process.
|
||||
|
||||
## Prepare Release
|
||||
|
||||
Set desired version as environment variable for following steps. Here is an example to release 2.1.3:
|
||||
|
||||
```
|
||||
export VERSION=v2.1.3
|
||||
export PREV_VERSION=v2.1.2
|
||||
```
|
||||
|
||||
All releases version numbers follow the format of [semantic versioning 2.0.0](http://semver.org/).
|
||||
|
||||
### Major, Minor Version Release, or its Pre-release
|
||||
|
||||
- Ensure the relevant milestone on GitHub is complete. All referenced issues should be closed, or moved elsewhere.
|
||||
- Remove this release from [roadmap](https://github.com/etcd-io/etcd/blob/master/ROADMAP.md), if necessary.
|
||||
- Ensure the latest upgrade documentation is available.
|
||||
- Bump [hardcoded MinClusterVerion in the repository](https://github.com/etcd-io/etcd/blob/master/version/version.go#L29), if necessary.
|
||||
- Add feature capability maps for the new version, if necessary.
|
||||
|
||||
### Patch Version Release
|
||||
|
||||
- Discuss about commits that are backported to the patch release. The commits should not include merge commits.
|
||||
- Cherry-pick these commits starting from the oldest one into stable branch.
|
||||
|
||||
## Write Release Note
|
||||
|
||||
|
||||
- Write introduction for the new release. For example, what major bug we fix, what new features we introduce or what performance improvement we make.
|
||||
- Write changelog for the last release. ChangeLog should be straightforward and easy to understand for the end-user.
|
||||
- Put `[GH XXXX]` at the head of change line to reference Pull Request that introduces the change. Moreover, add a link on it to jump to the Pull Request.
|
||||
|
||||
## Tag Version
|
||||
|
||||
- Bump [hardcoded Version in the repository](https://github.com/etcd-io/etcd/blob/master/version/version.go#L30) to the latest version `${VERSION}`.
|
||||
- Ensure all tests on CI system are passed.
|
||||
- Manually check etcd is buildable in Linux, Darwin and Windows.
|
||||
- Manually check upgrade etcd cluster of previous minor version works well.
|
||||
- Manually check new features work well.
|
||||
- Add a signed tag through `git tag -s ${VERSION}`.
|
||||
- Sanity check tag correctness through `git show tags/$VERSION`.
|
||||
- Push the tag to GitHub through `git push origin tags/$VERSION`. This assumes `origin` corresponds to "https://github.com/coreos/etcd".
|
||||
|
||||
## Build Release Binaries and Images
|
||||
|
||||
- Ensure `docker` is available.
|
||||
|
||||
Run release script in root directory:
|
||||
|
||||
```
|
||||
./scripts/release.sh ${VERSION}
|
||||
```
|
||||
|
||||
It generates all release binaries and images under directory ./release.
|
||||
|
||||
## Sign Binaries and Images
|
||||
|
||||
Choose appropriate private key to sign the generated binaries and images.
|
||||
|
||||
The following commands are used for public release sign:
|
||||
|
||||
```
|
||||
cd release
|
||||
# personal GPG is okay for now
|
||||
for i in etcd-*{.zip,.tar.gz}; do gpg --sign ${i}; done
|
||||
```
|
||||
|
||||
## Publish Release Page in GitHub
|
||||
|
||||
- Set release title as the version name.
|
||||
- Follow the format of previous release pages.
|
||||
- Attach the generated binaries, aci image and signatures.
|
||||
- Select whether it is a pre-release.
|
||||
- Publish the release!
|
||||
|
||||
## Publish Docker Image in Quay.io
|
||||
|
||||
- Push docker image:
|
||||
|
||||
```
|
||||
docker login quay.io
|
||||
docker push quay.io/coreos/etcd:${VERSION}
|
||||
docker push quay.io/coreos/etcd:${VERSION}-${arch}
|
||||
```
|
||||
|
||||
- Add `latest` tag to the new image on [quay.io](https://quay.io/repository/coreos/etcd?tag=latest&tab=tags) if this is a stable release.
|
||||
|
||||
## Announce to etcd-dev Googlegroup
|
||||
|
||||
- Follow the format of [previous release emails](https://groups.google.com/forum/#!forum/etcd-dev).
|
||||
- Make sure to include a list of authors that contributed since the previous release - something like the following might be handy:
|
||||
|
||||
```
|
||||
git log ...${PREV_VERSION} --pretty=format:"%an" | sort | uniq | tr '\n' ',' | sed -e 's#,#, #g' -e 's#, $##'
|
||||
```
|
||||
|
||||
- Send email to etcd-dev@googlegroups.com
|
||||
|
||||
## Post Release
|
||||
|
||||
- Create new stable branch through `git push origin ${VERSION_MAJOR}.${VERSION_MINOR}` if this is a major stable release. This assumes `origin` corresponds to "https://github.com/coreos/etcd".
|
||||
- Bump [hardcoded Version in the repository](https://github.com/etcd-io/etcd/blob/master/version/version.go#L30) to the version `${VERSION}+git`.
|
||||
|
|
@ -1,120 +0,0 @@
|
|||
---
|
||||
title: Discovery Service Protocol
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
Discovery service protocol helps new etcd member to discover all other members in cluster bootstrap phase using a shared discovery URL.
|
||||
|
||||
Discovery service protocol is _only_ used in cluster bootstrap phase, and cannot be used for runtime reconfiguration or cluster monitoring.
|
||||
|
||||
The protocol uses a new discovery token to bootstrap one _unique_ etcd cluster. Remember that one discovery token can represent only one etcd cluster. As long as discovery protocol on this token starts, even if it fails halfway, it must not be used to bootstrap another etcd cluster.
|
||||
|
||||
The rest of this article will walk through the discovery process with examples that correspond to a self-hosted discovery cluster. The public discovery service, discovery.etcd.io, functions the same way, but with a layer of polish to abstract away ugly URLs, generate UUIDs automatically, and provide some protections against excessive requests. At its core, the public discovery service still uses an etcd cluster as the data store as described in this document.
|
||||
|
||||
## The Protocol Workflow
|
||||
|
||||
The idea of discovery protocol is to use an internal etcd cluster to coordinate bootstrap of a new cluster. First, all new members interact with discovery service and help to generate the expected member list. Then each new member bootstraps its server using this list, which performs the same functionality as -initial-cluster flag.
|
||||
|
||||
In the following example workflow, we will list each step of protocol in curl format for ease of understanding.
|
||||
|
||||
By convention the etcd discovery protocol uses the key prefix `_etcd/registry`. If `http://example.com` hosts an etcd cluster for discovery service, a full URL to discovery keyspace will be `http://example.com/v2/keys/_etcd/registry`. We will use this as the URL prefix in the example.
|
||||
|
||||
### Creating a New Discovery Token
|
||||
|
||||
Generate a unique token that will identify the new cluster. This will be used as a unique prefix in discovery keyspace in the following steps. An easy way to do this is to use `uuidgen`:
|
||||
|
||||
```
|
||||
UUID=$(uuidgen)
|
||||
```
|
||||
|
||||
### Specifying the Expected Cluster Size
|
||||
|
||||
You need to specify the expected cluster size for this discovery token. The size is used by the discovery service to know when it has found all members that will initially form the cluster.
|
||||
|
||||
```
|
||||
curl -X PUT http://example.com/v2/keys/_etcd/registry/${UUID}/_config/size -d value=${cluster_size}
|
||||
```
|
||||
|
||||
Usually the cluster size is 3, 5 or 7. Check [optimal cluster size][cluster-size] for more details.
|
||||
|
||||
### Bringing up etcd Processes
|
||||
|
||||
Now that you have your discovery URL, you can use it as `-discovery` flag and bring up etcd processes. Every etcd process will follow this next few steps internally if given a `-discovery` flag.
|
||||
|
||||
### Registering itself
|
||||
|
||||
The first thing for etcd process is to register itself into the discovery URL as a member. This is done by creating member ID as a key in the discovery URL.
|
||||
|
||||
```
|
||||
curl -X PUT http://example.com/v2/keys/_etcd/registry/${UUID}/${member_id}?prevExist=false -d value="${member_name}=${member_peer_url_1}&${member_name}=${member_peer_url_2}"
|
||||
```
|
||||
|
||||
### Checking the Status
|
||||
|
||||
It checks the expected cluster size and registration status in discovery URL, and decides what the next action is.
|
||||
|
||||
```
|
||||
curl -X GET http://example.com/v2/keys/_etcd/registry/${UUID}/_config/size
|
||||
curl -X GET http://example.com/v2/keys/_etcd/registry/${UUID}
|
||||
```
|
||||
|
||||
If registered members are still not enough, it will wait for left members to appear.
|
||||
|
||||
If the number of registered members is bigger than the expected size N, it treats the first N registered members as the member list for the cluster. If the member itself is in the member list, the discovery procedure succeeds and it fetches all peers through the member list. If it is not in the member list, the discovery procedure finishes with the failure that the cluster has been full.
|
||||
|
||||
In etcd implementation, the member may check the cluster status even before registering itself. So it could fail quickly if the cluster has been full.
|
||||
|
||||
### Waiting for All Members
|
||||
|
||||
|
||||
The wait process is described in detail in the [etcd API documentation][api].
|
||||
|
||||
```
|
||||
curl -X GET http://example.com/v2/keys/_etcd/registry/${UUID}?wait=true&waitIndex=${current_etcd_index}
|
||||
```
|
||||
|
||||
It keeps waiting until finding all members.
|
||||
|
||||
## Public Discovery Service
|
||||
|
||||
CoreOS Inc. hosts a public discovery service at https://discovery.etcd.io/ , which provides some nice features for ease of use.
|
||||
|
||||
### Mask Key Prefix
|
||||
|
||||
Public discovery service will redirect `https://discovery.etcd.io/${UUID}` to etcd cluster behind for the key at `/v2/keys/_etcd/registry`. It masks register key prefix for short and readable discovery url.
|
||||
|
||||
### Get new token
|
||||
|
||||
```
|
||||
GET /new
|
||||
|
||||
Sent query:
|
||||
size=${cluster_size}
|
||||
Possible status codes:
|
||||
200 OK
|
||||
400 Bad Request
|
||||
200 Body:
|
||||
generated discovery url
|
||||
```
|
||||
|
||||
The generation process in the service follows the steps from [Creating a New Discovery Token][new-discovery-token] to [Specifying the Expected Cluster Size][expected-cluster-size].
|
||||
|
||||
### Check Discovery Status
|
||||
|
||||
```
|
||||
GET /${UUID}
|
||||
```
|
||||
|
||||
You can check the status for this discovery token, including the machines that have been registered, by requesting the value of the UUID.
|
||||
|
||||
### Open-source repository
|
||||
|
||||
The repository is located at https://github.com/coreos/discovery.etcd.io. You could use it to build your own public discovery service.
|
||||
|
||||
[api]: api.md#waiting-for-a-change
|
||||
[cluster-size]: admin_guide.md#optimal-cluster-size
|
||||
[expected-cluster-size]: #specifying-the-expected-cluster-size
|
||||
[new-discovery-token]: #creating-a-new-discovery-token
|
||||
|
|
@ -1,103 +0,0 @@
|
|||
---
|
||||
title: Running etcd under Docker
|
||||
---
|
||||
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
The following guide will show you how to run etcd under Docker using the [static bootstrap process](clustering.md#static).
|
||||
|
||||
## Running etcd in standalone mode
|
||||
|
||||
In order to expose the etcd API to clients outside of the Docker host you'll need use the host IP address when configuring etcd.
|
||||
|
||||
```
|
||||
export HostIP="192.168.12.50"
|
||||
```
|
||||
|
||||
The following `docker run` command will expose the etcd client API over ports 4001 and 2379, and expose the peer port over 2380.
|
||||
|
||||
This will run the latest release version of etcd. You can specify version if needed (e.g. `quay.io/coreos/etcd:v2.2.0`).
|
||||
|
||||
```
|
||||
docker run -d -v /usr/share/ca-certificates/:/etc/ssl/certs -p 4001:4001 -p 2380:2380 -p 2379:2379 \
|
||||
--name etcd quay.io/coreos/etcd:v2.3.8 \
|
||||
-name etcd0 \
|
||||
-advertise-client-urls http://${HostIP}:2379,http://${HostIP}:4001 \
|
||||
-listen-client-urls http://0.0.0.0:2379,http://0.0.0.0:4001 \
|
||||
-initial-advertise-peer-urls http://${HostIP}:2380 \
|
||||
-listen-peer-urls http://0.0.0.0:2380 \
|
||||
-initial-cluster-token etcd-cluster-1 \
|
||||
-initial-cluster etcd0=http://${HostIP}:2380 \
|
||||
-initial-cluster-state new
|
||||
```
|
||||
|
||||
Configure etcd clients to use the Docker host IP and one of the listening ports from above.
|
||||
|
||||
```
|
||||
etcdctl -C http://192.168.12.50:2379 member list
|
||||
```
|
||||
|
||||
```
|
||||
etcdctl -C http://192.168.12.50:4001 member list
|
||||
```
|
||||
|
||||
## Running a 3 node etcd cluster
|
||||
|
||||
Using Docker to setup a multi-node cluster is very similar to the standalone mode configuration.
|
||||
The main difference being the value used for the `-initial-cluster` flag, which must contain the peer urls for each etcd member in the cluster.
|
||||
|
||||
**Although the following commands look very similar, note that `-name`, `-advertise-client-urls` and `-initial-advertise-peer-urls` differ for each cluster member**
|
||||
|
||||
### etcd0
|
||||
|
||||
```
|
||||
docker run -d -v /usr/share/ca-certificates/:/etc/ssl/certs -p 4001:4001 -p 2380:2380 -p 2379:2379 \
|
||||
--name etcd quay.io/coreos/etcd:v2.3.8 \
|
||||
-name etcd0 \
|
||||
-advertise-client-urls http://192.168.12.50:2379,http://192.168.12.50:4001 \
|
||||
-listen-client-urls http://0.0.0.0:2379,http://0.0.0.0:4001 \
|
||||
-initial-advertise-peer-urls http://192.168.12.50:2380 \
|
||||
-listen-peer-urls http://0.0.0.0:2380 \
|
||||
-initial-cluster-token etcd-cluster-1 \
|
||||
-initial-cluster etcd0=http://192.168.12.50:2380,etcd1=http://192.168.12.51:2380,etcd2=http://192.168.12.52:2380 \
|
||||
-initial-cluster-state new
|
||||
```
|
||||
|
||||
### etcd1
|
||||
|
||||
```
|
||||
docker run -d -v /usr/share/ca-certificates/:/etc/ssl/certs -p 4001:4001 -p 2380:2380 -p 2379:2379 \
|
||||
--name etcd quay.io/coreos/etcd:v2.3.8 \
|
||||
-name etcd1 \
|
||||
-advertise-client-urls http://192.168.12.51:2379,http://192.168.12.51:4001 \
|
||||
-listen-client-urls http://0.0.0.0:2379,http://0.0.0.0:4001 \
|
||||
-initial-advertise-peer-urls http://192.168.12.51:2380 \
|
||||
-listen-peer-urls http://0.0.0.0:2380 \
|
||||
-initial-cluster-token etcd-cluster-1 \
|
||||
-initial-cluster etcd0=http://192.168.12.50:2380,etcd1=http://192.168.12.51:2380,etcd2=http://192.168.12.52:2380 \
|
||||
-initial-cluster-state new
|
||||
```
|
||||
|
||||
### etcd2
|
||||
|
||||
```
|
||||
docker run -d -v /usr/share/ca-certificates/:/etc/ssl/certs -p 4001:4001 -p 2380:2380 -p 2379:2379 \
|
||||
--name etcd quay.io/coreos/etcd:v2.3.8 \
|
||||
-name etcd2 \
|
||||
-advertise-client-urls http://192.168.12.52:2379,http://192.168.12.52:4001 \
|
||||
-listen-client-urls http://0.0.0.0:2379,http://0.0.0.0:4001 \
|
||||
-initial-advertise-peer-urls http://192.168.12.52:2380 \
|
||||
-listen-peer-urls http://0.0.0.0:2380 \
|
||||
-initial-cluster-token etcd-cluster-1 \
|
||||
-initial-cluster etcd0=http://192.168.12.50:2380,etcd1=http://192.168.12.51:2380,etcd2=http://192.168.12.52:2380 \
|
||||
-initial-cluster-state new
|
||||
```
|
||||
|
||||
Once the cluster has been bootstrapped etcd clients can be configured with a list of etcd members:
|
||||
|
||||
```
|
||||
etcdctl -C http://192.168.12.50:2379,http://192.168.12.51:2379,http://192.168.12.52:2379 member list
|
||||
```
|
||||
|
|
@ -1,47 +0,0 @@
|
|||
---
|
||||
title: Error Code
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
This document describes the error code used in key space '/v2/keys'. Feel free to import 'github.com/coreos/etcd/error' to use.
|
||||
|
||||
It's categorized into four groups:
|
||||
|
||||
- Command Related Error
|
||||
|
||||
| name | code | strerror |
|
||||
|----------------------|------|-----------------------|
|
||||
| EcodeKeyNotFound | 100 | "Key not found" |
|
||||
| EcodeTestFailed | 101 | "Compare failed" |
|
||||
| EcodeNotFile | 102 | "Not a file" |
|
||||
| EcodeNotDir | 104 | "Not a directory" |
|
||||
| EcodeNodeExist | 105 | "Key already exists" |
|
||||
| EcodeRootROnly | 107 | "Root is read only" |
|
||||
| EcodeDirNotEmpty | 108 | "Directory not empty" |
|
||||
|
||||
- Post Form Related Error
|
||||
|
||||
| name | code | strerror |
|
||||
|--------------------------|------|------------------------------------------------|
|
||||
| EcodePrevValueRequired | 201 | "PrevValue is Required in POST form" |
|
||||
| EcodeTTLNaN | 202 | "The given TTL in POST form is not a number" |
|
||||
| EcodeIndexNaN | 203 | "The given index in POST form is not a number" |
|
||||
| EcodeInvalidField | 209 | "Invalid field" |
|
||||
| EcodeInvalidForm | 210 | "Invalid POST form" |
|
||||
|
||||
- Raft Related Error
|
||||
|
||||
| name | code | strerror |
|
||||
|-------------------|------|--------------------------|
|
||||
| EcodeRaftInternal | 300 | "Raft Internal Error" |
|
||||
| EcodeLeaderElect | 301 | "During Leader Election" |
|
||||
|
||||
- Etcd Related Error
|
||||
|
||||
| name | code | strerror |
|
||||
|-------------------------|------|--------------------------------------------------------|
|
||||
| EcodeWatcherCleared | 400 | "watcher is cleared due to etcd recovery" |
|
||||
| EcodeEventIndexCleared | 401 | "The event in requested index is outdated and cleared" |
|
||||
|
|
@ -1,121 +0,0 @@
|
|||
### General cluster availability ###
|
||||
|
||||
# alert if another failed member will result in an unavailable cluster
|
||||
ALERT InsufficientMembers
|
||||
IF count(up{job="etcd"} == 0) > (count(up{job="etcd"}) / 2 - 1)
|
||||
FOR 3m
|
||||
LABELS {
|
||||
severity = "critical"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "etcd cluster insufficient members",
|
||||
description = "If one more etcd member goes down the cluster will be unavailable",
|
||||
}
|
||||
|
||||
### HTTP requests alerts ###
|
||||
|
||||
# alert if more than 1% of requests to an HTTP endpoint have failed with a non 4xx response
|
||||
ALERT HighNumberOfFailedHTTPRequests
|
||||
IF sum by(method) (rate(etcd_http_failed_total{job="etcd", code!~"4[0-9]{2}"}[5m]))
|
||||
/ sum by(method) (rate(etcd_http_received_total{job="etcd"}[5m])) > 0.01
|
||||
FOR 10m
|
||||
LABELS {
|
||||
severity = "warning"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "a high number of HTTP requests are failing",
|
||||
description = "{{ $value }}% of requests for {{ $labels.method }} failed on etcd instance {{ $labels.instance }}",
|
||||
}
|
||||
|
||||
# alert if more than 5% of requests to an HTTP endpoint have failed with a non 4xx response
|
||||
ALERT HighNumberOfFailedHTTPRequests
|
||||
IF sum by(method) (rate(etcd_http_failed_total{job="etcd", code!~"4[0-9]{2}"}[5m]))
|
||||
/ sum by(method) (rate(etcd_http_received_total{job="etcd"}[5m])) > 0.05
|
||||
FOR 5m
|
||||
LABELS {
|
||||
severity = "critical"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "a high number of HTTP requests are failing",
|
||||
description = "{{ $value }}% of requests for {{ $labels.method }} failed on etcd instance {{ $labels.instance }}",
|
||||
}
|
||||
|
||||
# alert if 50% of requests get a 4xx response
|
||||
ALERT HighNumberOfFailedHTTPRequests
|
||||
IF sum by(method) (rate(etcd_http_failed_total{job="etcd", code=~"4[0-9]{2}"}[5m]))
|
||||
/ sum by(method) (rate(etcd_http_received_total{job="etcd"}[5m])) > 0.5
|
||||
FOR 10m
|
||||
LABELS {
|
||||
severity = "critical"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "a high number of HTTP requests are failing",
|
||||
description = "{{ $value }}% of requests for {{ $labels.method }} failed with 4xx responses on etcd instance {{ $labels.instance }}",
|
||||
}
|
||||
|
||||
# alert if the 99th percentile of HTTP requests take more than 150ms
|
||||
ALERT HTTPRequestsSlow
|
||||
IF histogram_quantile(0.99, rate(etcd_http_successful_duration_second_bucket[5m])) > 0.15
|
||||
FOR 10m
|
||||
LABELS {
|
||||
severity = "warning"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "slow HTTP requests",
|
||||
description = "on etcd instance {{ $labels.instance }} HTTP requests to {{ $labels.method }} are slow",
|
||||
}
|
||||
|
||||
### File descriptor alerts ###
|
||||
|
||||
instance:fd_utilization = process_open_fds / process_max_fds
|
||||
|
||||
# alert if file descriptors are likely to exhaust within the next 4 hours
|
||||
ALERT FdExhaustionClose
|
||||
IF predict_linear(instance:fd_utilization[1h], 3600 * 4) > 1
|
||||
FOR 10m
|
||||
LABELS {
|
||||
severity = "warning"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "file descriptors soon exhausted",
|
||||
description = "{{ $labels.job }} instance {{ $labels.instance }} will exhaust its file descriptors soon",
|
||||
}
|
||||
|
||||
# alert if file descriptors are likely to exhaust within the next hour
|
||||
ALERT FdExhaustionClose
|
||||
IF predict_linear(instance:fd_utilization[10m], 3600) > 1
|
||||
FOR 10m
|
||||
LABELS {
|
||||
severity = "critical"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "file descriptors soon exhausted",
|
||||
description = "{{ $labels.job }} instance {{ $labels.instance }} will exhaust its file descriptors soon",
|
||||
}
|
||||
|
||||
### etcd proposal alerts ###
|
||||
|
||||
# alert if there are several failed proposals within an hour
|
||||
ALERT HighNumberOfFailedProposals
|
||||
IF increase(etcd_server_proposal_failed_total{job="etcd"}[1h]) > 5
|
||||
LABELS {
|
||||
severity = "warning"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "a high number of proposals within the etcd cluster are failing",
|
||||
description = "etcd instance {{ $labels.instance }} has seen {{ $value }} proposal failures within the last hour",
|
||||
}
|
||||
|
||||
### etcd disk io latency alerts ###
|
||||
|
||||
# alert if 99th percentile of fsync durations is higher than 500ms
|
||||
ALERT HighFsyncDurations
|
||||
IF histogram_quantile(0.99, rate(etcd_wal_fsync_durations_seconds_bucket[5m])) > 0.5
|
||||
FOR 10m
|
||||
LABELS {
|
||||
severity = "warning"
|
||||
}
|
||||
ANNOTATIONS {
|
||||
summary = "high fsync durations",
|
||||
description = "etcd instance {{ $labels.instance }} fync durations are high",
|
||||
}
|
||||
|
|
@ -1,91 +0,0 @@
|
|||
groups:
|
||||
- name: etcd_alert.rules
|
||||
rules:
|
||||
- alert: InsufficientMembers
|
||||
expr: count(up{job="etcd"} == 0) > (count(up{job="etcd"}) / 2 - 1)
|
||||
for: 3m
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
description: If one more etcd member goes down the cluster will be unavailable
|
||||
summary: etcd cluster insufficient members
|
||||
- alert: HighNumberOfFailedHTTPRequests
|
||||
expr: sum(rate(etcd_http_failed_total{code!~"^(?:4[0-9]{2})$",job="etcd"}[5m]))
|
||||
BY (method) / sum(rate(etcd_http_received_total{job="etcd"}[5m])) BY (method)
|
||||
> 0.01
|
||||
for: 10m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
description: '{{ $value }}% of requests for {{ $labels.method }} failed on etcd
|
||||
instance {{ $labels.instance }}'
|
||||
summary: a high number of HTTP requests are failing
|
||||
- alert: HighNumberOfFailedHTTPRequests
|
||||
expr: sum(rate(etcd_http_failed_total{code!~"^(?:4[0-9]{2})$",job="etcd"}[5m]))
|
||||
BY (method) / sum(rate(etcd_http_received_total{job="etcd"}[5m])) BY (method)
|
||||
> 0.05
|
||||
for: 5m
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
description: '{{ $value }}% of requests for {{ $labels.method }} failed on etcd
|
||||
instance {{ $labels.instance }}'
|
||||
summary: a high number of HTTP requests are failing
|
||||
- alert: HighNumberOfFailedHTTPRequests
|
||||
expr: sum(rate(etcd_http_failed_total{code=~"^(?:4[0-9]{2})$",job="etcd"}[5m]))
|
||||
BY (method) / sum(rate(etcd_http_received_total{job="etcd"}[5m])) BY (method)
|
||||
> 0.5
|
||||
for: 10m
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
description: '{{ $value }}% of requests for {{ $labels.method }} failed with
|
||||
4xx responses on etcd instance {{ $labels.instance }}'
|
||||
summary: a high number of HTTP requests are failing
|
||||
- alert: HTTPRequestsSlow
|
||||
expr: histogram_quantile(0.99, rate(etcd_http_successful_duration_second_bucket[5m]))
|
||||
> 0.15
|
||||
for: 10m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
description: on etcd instance {{ $labels.instance }} HTTP requests to {{ $labels.method
|
||||
}} are slow
|
||||
summary: slow HTTP requests
|
||||
- record: instance:fd_utilization
|
||||
expr: process_open_fds / process_max_fds
|
||||
- alert: FdExhaustionClose
|
||||
expr: predict_linear(instance:fd_utilization[1h], 3600 * 4) > 1
|
||||
for: 10m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
description: '{{ $labels.job }} instance {{ $labels.instance }} will exhaust
|
||||
its file descriptors soon'
|
||||
summary: file descriptors soon exhausted
|
||||
- alert: FdExhaustionClose
|
||||
expr: predict_linear(instance:fd_utilization[10m], 3600) > 1
|
||||
for: 10m
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
description: '{{ $labels.job }} instance {{ $labels.instance }} will exhaust
|
||||
its file descriptors soon'
|
||||
summary: file descriptors soon exhausted
|
||||
- alert: HighNumberOfFailedProposals
|
||||
expr: increase(etcd_server_proposal_failed_total{job="etcd"}[1h]) > 5
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
description: etcd instance {{ $labels.instance }} has seen {{ $value }} proposal
|
||||
failures within the last hour
|
||||
summary: a high number of proposals within the etcd cluster are failing
|
||||
- alert: HighFsyncDurations
|
||||
expr: histogram_quantile(0.99, rate(etcd_wal_fsync_durations_seconds_bucket[5m]))
|
||||
> 0.5
|
||||
for: 10m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
description: etcd instance {{ $labels.instance }} fync durations are high
|
||||
summary: high fsync durations
|
||||
|
|
@ -1,89 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# FAQ
|
||||
|
||||
## 1) Why can an etcd client read an old version of data when a majority of the etcd cluster members are down?
|
||||
|
||||
In situations where a client connects to a minority, etcd
|
||||
favors by default availability over consistency. This means that even though
|
||||
data might be “out of date”, it is still better to return something versus
|
||||
nothing.
|
||||
|
||||
In order to confirm that a read is up to date with a majority of the cluster,
|
||||
the client can use the `quorum=true` parameter on reads of keys. This means
|
||||
that a majority of the cluster is checked on reads before returning the data,
|
||||
otherwise the read will timeout and fail.
|
||||
|
||||
## 2) With quorum=false, doesn’t this mean that if my client switched the member it was connected to, that it could experience a logical ordering where the cluster goes backwards in time?
|
||||
|
||||
Yes, but this could be handled at the etcd client implementation via
|
||||
remembering the last seen index. The “index” is the cluster's single
|
||||
irrevocable sequence of the entire modification history. The client could
|
||||
remember the last seen index, and determine via comparing the index returned on
|
||||
the GET whether or not the state of the key-value pair is before or after its
|
||||
last seen state.
|
||||
|
||||
## 3) What happens if a watch is registered on a minority member?
|
||||
|
||||
The watch will stay untriggered, even as modifications are occurring in the
|
||||
majority quorum. This is an open issue, and is being addressed in v3. There are
|
||||
multiple ways to work around the watch trigger not firing.
|
||||
|
||||
1) build a signaling mechanism independent of etcd. This could be as simple as
|
||||
a “pulse” to the client to reissue a GET with quorum=true for the most recent
|
||||
version of the data.
|
||||
|
||||
2) poll on the `/v2/keys` endpoint and check that the raft-index is increasing every
|
||||
timeout.
|
||||
|
||||
## 4) What is a proxy used for?
|
||||
|
||||
A proxy is a redirection server to the etcd cluster. The proxy handles the
|
||||
redirection of a client to the current configuration of the etcd cluster. A
|
||||
typical use case is to start a proxy on a machine, and on first boot up of the
|
||||
proxy specify both the `--proxy` flag and the `--initial-cluster` flag.
|
||||
|
||||
From there, any etcdctl client that starts up automatically speaks to the local
|
||||
proxy and the proxy redirects operations to the current configuration of the
|
||||
cluster it was originally paired with.
|
||||
|
||||
In the v2 spec of etcd, proxies cannot be promoted to members of the cluster.
|
||||
They also cannot be promoted to followers or at any point become part of the
|
||||
replication of the etcd cluster itself.
|
||||
|
||||
## 5) How is cluster membership and health handled in etcd v2?
|
||||
|
||||
The design goal of etcd is that reconfiguration is simply an API, and health
|
||||
monitoring and addition/removal of members is up to the individual application
|
||||
and their integration with the reconfiguration API.
|
||||
|
||||
Thus, a member that is down, even infinitely, will never be automatically
|
||||
removed from the etcd cluster member list.
|
||||
|
||||
This makes sense because it's usually an application level / administrative
|
||||
action to determine whether a reconfiguration should happen based on health.
|
||||
|
||||
For more information, refer to the [runtime reconfiguration design document][runtime-reconf-design].
|
||||
|
||||
## 6) how does --endpoint work with etcdctl?
|
||||
|
||||
The `--endpoint` flag can specify any number of etcd cluster members in a comma
|
||||
separated list. This list might be a subset, equal to, or more than the actual
|
||||
etcd cluster member list itself.
|
||||
|
||||
If only one peer is specified via the `--endpoint` flag, the etcdctl discovers the
|
||||
rest of the cluster via the member list of that one peer, and then it randomly
|
||||
chooses a member to use. Again, the client can use the `quorum=true` flag on
|
||||
reads, which will always fail when using a member in the minority.
|
||||
|
||||
If peers from multiple clusters are specified via the `--endpoint` flag, etcdctl
|
||||
will randomly choose a peer, and the request will simply get routed to one of
|
||||
the clusters. This is probably not what you want.
|
||||
|
||||
Note: --peers flag is now deprecated and --endpoint should be used instead,
|
||||
as it might confuse users to give etcdctl a peerURL.
|
||||
|
||||
[runtime-reconf-design]: runtime-reconf-design.md
|
||||
|
|
@ -1,40 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# Glossary
|
||||
|
||||
This document defines the various terms used in etcd documentation, command line and source code.
|
||||
|
||||
## Node
|
||||
|
||||
Node is an instance of raft state machine.
|
||||
|
||||
It has a unique identification, and records other nodes' progress internally when it is the leader.
|
||||
|
||||
## Member
|
||||
|
||||
Member is an instance of etcd. It hosts a node, and provides service to clients.
|
||||
|
||||
## Cluster
|
||||
|
||||
Cluster consists of several members.
|
||||
|
||||
The node in each member follows raft consensus protocol to replicate logs. Cluster receives proposals from members, commits them and apply to local store.
|
||||
|
||||
## Peer
|
||||
|
||||
Peer is another member of the same cluster.
|
||||
|
||||
## Proposal
|
||||
|
||||
A proposal is a request (for example a write request, a configuration change request) that needs to go through raft protocol.
|
||||
|
||||
## Client
|
||||
|
||||
Client is a caller of the cluster's HTTP API.
|
||||
|
||||
## Machine (deprecated)
|
||||
|
||||
The alternative of Member in etcd before 2.0
|
||||
|
|
@ -1,66 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# Versioning
|
||||
|
||||
Goal: We want to be able to upgrade an individual peer in an etcd cluster to a newer version of etcd.
|
||||
The process will take the form of individual followers upgrading to the latest version until the entire cluster is on the new version.
|
||||
|
||||
Immediate need: etcd is moving too fast to version the internal API right now.
|
||||
But, we need to keep mixed version clusters from being started by a rolling upgrade process (e.g. the CoreOS developer alpha).
|
||||
|
||||
Longer term need: Having a mixed version cluster where all peers are not running the exact same version of etcd itself but are able to speak one version of the internal protocol.
|
||||
|
||||
Solution: The internal protocol needs to be versioned just as the client protocol is.
|
||||
Initially during the 0.\*.\* series of etcd releases we won't allow mixed versions at all.
|
||||
|
||||
## Join Control
|
||||
|
||||
We will add a version field to the join command.
|
||||
But, who decides whether a newly upgraded follower should be able to join a cluster?
|
||||
|
||||
### Leader Controlled
|
||||
|
||||
If the leader controls the version of followers joining the cluster then it compares its version to the version number presented by the follower in the JoinCommand and rejects the join if the number is less than the leader's version number.
|
||||
|
||||
Advantages
|
||||
|
||||
- Leader controls all cluster decisions still
|
||||
|
||||
Disadvantages
|
||||
|
||||
- Follower knows better what versions of the internal protocol it can talk than the leader
|
||||
|
||||
|
||||
### Follower Controlled
|
||||
|
||||
A newly upgraded follower should be able to figure out the leaders internal version from a defined internal backwards compatible API endpoint and figure out if it can join the cluster.
|
||||
If it cannot join the cluster then it simply exits.
|
||||
|
||||
Advantages
|
||||
|
||||
- The follower is running newer code and knows better if it can talk older protocols
|
||||
|
||||
Disadvantages
|
||||
|
||||
- This cluster decision isn't made by the leader
|
||||
|
||||
## Recommendation
|
||||
|
||||
To solve the immediate need and to plan for the future lets do the following:
|
||||
|
||||
- Add Version field to JoinCommand
|
||||
- Have a joining follower read the Version field of the leader and if its own version doesn't match the leader then sleep for some random interval and retry later to see if the leader has upgraded.
|
||||
|
||||
# Research
|
||||
|
||||
## Zookeeper versioning
|
||||
|
||||
Zookeeper very recently added versioning into the protocol and it doesn't seem to have seen any use yet.
|
||||
https://issues.apache.org/jira/browse/ZOOKEEPER-1633
|
||||
|
||||
## doozerd
|
||||
|
||||
doozerd stores the version number of the peers in the datastore for other clients to check, no decisions are made off of this number currently.
|
||||
|
|
@ -1,130 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# Libraries and Tools
|
||||
|
||||
**Tools**
|
||||
|
||||
- [etcdctl](https://github.com/coreos/etcd/tree/master/etcdctl) - A command line client for etcd
|
||||
- [etcd-backup](https://github.com/fanhattan/etcd-backup) - A powerful command line utility for dumping/restoring etcd - Supports v2
|
||||
- [etcd-dump](https://npmjs.org/package/etcd-dump) - Command line utility for dumping/restoring etcd.
|
||||
- [etcd-fs](https://github.com/xetorthio/etcd-fs) - FUSE filesystem for etcd
|
||||
- [etcddir](https://github.com/rekby/etcddir) - Realtime sync etcd and local directory. Work with windows and linux.
|
||||
- [etcd-browser](https://github.com/henszey/etcd-browser) - A web-based key/value editor for etcd using AngularJS
|
||||
- [etcd-lock](https://github.com/datawisesystems/etcd-lock) - Master election & distributed r/w lock implementation using etcd - Supports v2
|
||||
- [etcd-console](https://github.com/matishsiao/etcd-console) - A web-base key/value editor for etcd using PHP
|
||||
- [etcd-viewer](https://github.com/nikfoundas/etcd-viewer) - An etcd key-value store editor/viewer written in Java
|
||||
- [etcdtool](https://github.com/mickep76/etcdtool) - Export/Import/Edit etcd directory as JSON/YAML/TOML and Validate directory using JSON schema
|
||||
- [etcd-rest](https://github.com/mickep76/etcd-rest) - Create generic REST API in Go using etcd as a backend with validation using JSON schema
|
||||
- [etcdsh](https://github.com/kamilhark/etcdsh) - A command line client with support of command history and tab completion. Supports v2
|
||||
|
||||
**Go libraries**
|
||||
|
||||
- [etcd/client](https://github.com/etcd-io/etcd/blob/master/client) - the officially maintained Go client
|
||||
- [go-etcd](https://github.com/coreos/go-etcd) - the deprecated official client. May be useful for older (<2.0.0) versions of etcd.
|
||||
|
||||
**Java libraries**
|
||||
|
||||
- [boonproject/etcd](https://github.com/boonproject/boon/blob/master/etcd/README.md) - Supports v2, Async/Sync and waits
|
||||
- [justinsb/jetcd](https://github.com/justinsb/jetcd)
|
||||
- [diwakergupta/jetcd](https://github.com/diwakergupta/jetcd) - Supports v2
|
||||
- [jurmous/etcd4j](https://github.com/jurmous/etcd4j) - Supports v2, Async/Sync, waits and SSL
|
||||
- [AdoHe/etcd4j](http://github.com/AdoHe/etcd4j) - Supports v2 (enhance for real production cluster)
|
||||
|
||||
**Python libraries**
|
||||
|
||||
- [jplana/python-etcd](https://github.com/jplana/python-etcd) - Supports v2
|
||||
- [russellhaering/txetcd](https://github.com/russellhaering/txetcd) - a Twisted Python library
|
||||
- [cholcombe973/autodock](https://github.com/cholcombe973/autodock) - A docker deployment automation tool
|
||||
- [lisael/aioetcd](https://github.com/lisael/aioetcd) - (Python 3.4+) Asyncio coroutines client (Supports v2)
|
||||
|
||||
**Node libraries**
|
||||
|
||||
- [stianeikeland/node-etcd](https://github.com/stianeikeland/node-etcd) - Supports v2 (w Coffeescript)
|
||||
- [lavagetto/nodejs-etcd](https://github.com/lavagetto/nodejs-etcd) - Supports v2
|
||||
- [deedubs/node-etcd-config](https://github.com/deedubs/node-etcd-config) - Supports v2
|
||||
|
||||
**Ruby libraries**
|
||||
|
||||
- [iconara/etcd-rb](https://github.com/iconara/etcd-rb)
|
||||
- [jpfuentes2/etcd-ruby](https://github.com/jpfuentes2/etcd-ruby)
|
||||
- [ranjib/etcd-ruby](https://github.com/ranjib/etcd-ruby) - Supports v2
|
||||
|
||||
**C libraries**
|
||||
|
||||
- [jdarcy/etcd-api](https://github.com/jdarcy/etcd-api) - Supports v2
|
||||
- [shafreeck/cetcd](https://github.com/shafreeck/cetcd) - Supports v2
|
||||
|
||||
**C++ libraries**
|
||||
|
||||
- [edwardcapriolo/etcdcpp](https://github.com/edwardcapriolo/etcdcpp) - Supports v2
|
||||
- [suryanathan/etcdcpp](https://github.com/suryanathan/etcdcpp) - Supports v2 (with waits)
|
||||
- [nokia/etcd-cpp-api](https://github.com/nokia/etcd-cpp-api) - Supports v2
|
||||
- [nokia/etcd-cpp-apiv3](https://github.com/nokia/etcd-cpp-apiv3)
|
||||
|
||||
**Clojure libraries**
|
||||
|
||||
- [aterreno/etcd-clojure](https://github.com/aterreno/etcd-clojure)
|
||||
- [dwwoelfel/cetcd](https://github.com/dwwoelfel/cetcd) - Supports v2
|
||||
- [rthomas/clj-etcd](https://github.com/rthomas/clj-etcd) - Supports v2
|
||||
|
||||
**Erlang libraries**
|
||||
|
||||
- [marshall-lee/etcd.erl](https://github.com/marshall-lee/etcd.erl)
|
||||
|
||||
**.Net Libraries**
|
||||
|
||||
- [wangjia184/etcdnet](https://github.com/wangjia184/etcdnet) - Supports v2
|
||||
- [drusellers/etcetera](https://github.com/drusellers/etcetera)
|
||||
|
||||
**PHP Libraries**
|
||||
|
||||
- [linkorb/etcd-php](https://github.com/linkorb/etcd-php)
|
||||
|
||||
**Haskell libraries**
|
||||
|
||||
- [wereHamster/etcd-hs](https://github.com/wereHamster/etcd-hs)
|
||||
|
||||
**R libraries**
|
||||
|
||||
- [ropensci/etseed](https://github.com/ropensci/etseed)
|
||||
|
||||
**Tcl libraries**
|
||||
|
||||
- [efrecon/etcd-tcl](https://github.com/efrecon/etcd-tcl) - Supports v2, except wait.
|
||||
|
||||
**Chef Integration**
|
||||
|
||||
- [coderanger/etcd-chef](https://github.com/coderanger/etcd-chef)
|
||||
|
||||
**Chef Cookbook**
|
||||
|
||||
- [spheromak/etcd-cookbook](https://github.com/spheromak/etcd-cookbook)
|
||||
|
||||
**BOSH Releases**
|
||||
|
||||
- [cloudfoundry-community/etcd-boshrelease](https://github.com/cloudfoundry-community/etcd-boshrelease)
|
||||
- [cloudfoundry/cf-release](https://github.com/cloudfoundry/cf-release/tree/master/jobs/etcd)
|
||||
|
||||
**Projects using etcd**
|
||||
|
||||
- [binocarlos/yoda](https://github.com/binocarlos/yoda) - etcd + ZeroMQ
|
||||
- [calavera/active-proxy](https://github.com/calavera/active-proxy) - HTTP Proxy configured with etcd
|
||||
- [derekchiang/etcdplus](https://github.com/derekchiang/etcdplus) - A set of distributed synchronization primitives built upon etcd
|
||||
- [go-discover](https://github.com/flynn/go-discover) - service discovery in Go
|
||||
- [gleicon/goreman](https://github.com/gleicon/goreman/tree/etcd) - Branch of the Go Foreman clone with etcd support
|
||||
- [garethr/hiera-etcd](https://github.com/garethr/hiera-etcd) - Puppet hiera backend using etcd
|
||||
- [mattn/etcd-vim](https://github.com/mattn/etcd-vim) - SET and GET keys from inside vim
|
||||
- [mattn/etcdenv](https://github.com/mattn/etcdenv) - "env" shebang with etcd integration
|
||||
- [kelseyhightower/confd](https://github.com/kelseyhightower/confd) - Manage local app config files using templates and data from etcd
|
||||
- [configdb](https://git.autistici.org/ai/configdb/tree/master) - A REST relational abstraction on top of arbitrary database backends, aimed at storing configs and inventories.
|
||||
- [kubernetes/kubernetes](https://github.com/kubernetes/kubernetes) - Container cluster manager introduced by Google.
|
||||
- [mailgun/vulcand](https://github.com/mailgun/vulcand) - HTTP proxy that uses etcd as a configuration backend.
|
||||
- [duedil-ltd/discodns](https://github.com/duedil-ltd/discodns) - Simple DNS nameserver using etcd as a database for names and records.
|
||||
- [skynetservices/skydns](https://github.com/skynetservices/skydns) - RFC compliant DNS server
|
||||
- [xordataexchange/crypt](https://github.com/xordataexchange/crypt) - Securely store values in etcd using GPG encryption
|
||||
- [spf13/viper](https://github.com/spf13/viper) - Go configuration library, reads values from ENV, pflags, files, and etcd with optional encryption
|
||||
- [lytics/metafora](https://github.com/lytics/metafora) - Go distributed task library
|
||||
- [ryandoyle/nss-etcd](https://github.com/ryandoyle/nss-etcd) - A GNU libc NSS module for resolving names from etcd.
|
||||
|
|
@ -1,125 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# Members API
|
||||
|
||||
* [List members](#list-members)
|
||||
* [Add a member](#add-a-member)
|
||||
* [Delete a member](#delete-a-member)
|
||||
* [Change the peer urls of a member](#change-the-peer-urls-of-a-member)
|
||||
|
||||
## List members
|
||||
|
||||
Return an HTTP 200 OK response code and a representation of all members in the etcd cluster.
|
||||
|
||||
### Request
|
||||
|
||||
```
|
||||
GET /v2/members HTTP/1.1
|
||||
```
|
||||
|
||||
### Example
|
||||
|
||||
```sh
|
||||
curl http://10.0.0.10:2379/v2/members
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"members": [
|
||||
{
|
||||
"id": "272e204152",
|
||||
"name": "infra1",
|
||||
"peerURLs": [
|
||||
"http://10.0.0.10:2380"
|
||||
],
|
||||
"clientURLs": [
|
||||
"http://10.0.0.10:2379"
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "2225373f43",
|
||||
"name": "infra2",
|
||||
"peerURLs": [
|
||||
"http://10.0.0.11:2380"
|
||||
],
|
||||
"clientURLs": [
|
||||
"http://10.0.0.11:2379"
|
||||
]
|
||||
},
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Add a member
|
||||
|
||||
Returns an HTTP 201 response code and the representation of added member with a newly generated a memberID when successful. Returns a string describing the failure condition when unsuccessful.
|
||||
|
||||
If the POST body is malformed an HTTP 400 will be returned. If the member exists in the cluster or existed in the cluster at some point in the past an HTTP 409 will be returned. If any of the given peerURLs exists in the cluster an HTTP 409 will be returned. If the cluster fails to process the request within timeout an HTTP 500 will be returned, though the request may be processed later.
|
||||
|
||||
### Request
|
||||
|
||||
```
|
||||
POST /v2/members HTTP/1.1
|
||||
|
||||
{"peerURLs": ["http://10.0.0.10:2380"]}
|
||||
```
|
||||
|
||||
### Example
|
||||
|
||||
```sh
|
||||
curl http://10.0.0.10:2379/v2/members -XPOST \
|
||||
-H "Content-Type: application/json" -d '{"peerURLs":["http://10.0.0.10:2380"]}'
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "3777296169",
|
||||
"peerURLs": [
|
||||
"http://10.0.0.10:2380"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Delete a member
|
||||
|
||||
Remove a member from the cluster. The member ID must be a hex-encoded uint64.
|
||||
Returns 204 with empty content when successful. Returns a string describing the failure condition when unsuccessful.
|
||||
|
||||
If the member does not exist in the cluster an HTTP 500(TODO: fix this) will be returned. If the cluster fails to process the request within timeout an HTTP 500 will be returned, though the request may be processed later.
|
||||
|
||||
### Request
|
||||
|
||||
```
|
||||
DELETE /v2/members/<id> HTTP/1.1
|
||||
```
|
||||
|
||||
### Example
|
||||
|
||||
```sh
|
||||
curl http://10.0.0.10:2379/v2/members/272e204152 -XDELETE
|
||||
```
|
||||
|
||||
## Change the peer urls of a member
|
||||
|
||||
Change the peer urls of a given member. The member ID must be a hex-encoded uint64. Returns 204 with empty content when successful. Returns a string describing the failure condition when unsuccessful.
|
||||
|
||||
If the POST body is malformed an HTTP 400 will be returned. If the member does not exist in the cluster an HTTP 404 will be returned. If any of the given peerURLs exists in the cluster an HTTP 409 will be returned. If the cluster fails to process the request within timeout an HTTP 500 will be returned, though the request may be processed later.
|
||||
|
||||
### Request
|
||||
|
||||
```
|
||||
PUT /v2/members/<id> HTTP/1.1
|
||||
|
||||
{"peerURLs": ["http://10.0.0.10:2380"]}
|
||||
```
|
||||
|
||||
### Example
|
||||
|
||||
```sh
|
||||
curl http://10.0.0.10:2379/v2/members/272e204152 -XPUT \
|
||||
-H "Content-Type: application/json" -d '{"peerURLs":["http://10.0.0.10:2380"]}'
|
||||
```
|
||||
|
||||
|
|
@ -1,148 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# Metrics
|
||||
|
||||
etcd uses [Prometheus][prometheus] for metrics reporting. The metrics can be used for real-time monitoring and debugging. etcd does not persist its metrics; if a member restarts, the metrics will be reset.
|
||||
|
||||
The simplest way to see the available metrics is to cURL the metrics endpoint `/metrics`. The format is described [here](http://prometheus.io/docs/instrumenting/exposition_formats/).
|
||||
|
||||
Follow the [Prometheus getting started doc][prometheus-getting-started] to spin up a Prometheus server to collect etcd metrics.
|
||||
|
||||
The naming of metrics follows the suggested [Prometheus best practices][prometheus-naming]. A metric name has an `etcd` or `etcd_debugging` prefix as its namespace and a subsystem prefix (for example `wal` and `etcdserver`).
|
||||
|
||||
## etcd namespace metrics
|
||||
|
||||
The metrics under the `etcd` prefix are for monitoring and alerting. They are stable high level metrics. If there is any change of these metrics, it will be included in release notes.
|
||||
|
||||
### http requests
|
||||
|
||||
These metrics describe the serving of requests (non-watch events) served by etcd members in non-proxy mode: total
|
||||
incoming requests, request failures and processing latency (inc. raft rounds for storage). They are useful for tracking
|
||||
user-generated traffic hitting the etcd cluster .
|
||||
|
||||
All these metrics are prefixed with `etcd_http_`
|
||||
|
||||
| Name | Description | Type |
|
||||
|--------------------------------|-----------------------------------------------------------------------------------------|--------------------|
|
||||
| received_total | Total number of events after parsing and auth. | Counter(method) |
|
||||
| failed_total | Total number of failed events. | Counter(method,error) |
|
||||
| successful_duration_seconds | Bucketed handling times of the requests, including raft rounds for writes. | Histogram(method) |
|
||||
|
||||
|
||||
Example Prometheus queries that may be useful from these metrics (across all etcd members):
|
||||
|
||||
* `sum(rate(etcd_http_failed_total{job="etcd"}[1m]) by (method) / sum(rate(etcd_http_events_received_total{job="etcd"})[1m]) by (method)`
|
||||
|
||||
Shows the fraction of events that failed by HTTP method across all members, across a time window of `1m`.
|
||||
|
||||
* `sum(rate(etcd_http_received_total{job="etcd",method="GET})[1m]) by (method)`
|
||||
`sum(rate(etcd_http_received_total{job="etcd",method~="GET})[1m]) by (method)`
|
||||
|
||||
Shows the rate of successful readonly/write queries across all servers, across a time window of `1m`.
|
||||
|
||||
* `histogram_quantile(0.9, sum(rate(etcd_http_successful_duration_seconds{job="etcd",method="GET"}[5m]) ) by (le))`
|
||||
`histogram_quantile(0.9, sum(rate(etcd_http_successful_duration_seconds{job="etcd",method!="GET"}[5m]) ) by (le))`
|
||||
|
||||
Show the 0.90-tile latency (in seconds) of read/write (respectively) event handling across all members, with a window of `5m`.
|
||||
|
||||
### proxy
|
||||
|
||||
etcd members operating in proxy mode do not directly perform store operations. They forward all requests to cluster instances.
|
||||
|
||||
Tracking the rate of requests coming from a proxy allows one to pin down which machine is performing most reads/writes.
|
||||
|
||||
All these metrics are prefixed with `etcd_proxy_`
|
||||
|
||||
| Name | Description | Type |
|
||||
|---------------------------|-----------------------------------------------------------------------------------------|--------------------|
|
||||
| requests_total | Total number of requests by this proxy instance. | Counter(method) |
|
||||
| handled_total | Total number of fully handled requests, with responses from etcd members. | Counter(method) |
|
||||
| dropped_total | Total number of dropped requests due to forwarding errors to etcd members. | Counter(method,error) |
|
||||
| handling_duration_seconds | Bucketed handling times by HTTP method, including round trip to member instances. | Histogram(method) |
|
||||
|
||||
Example Prometheus queries that may be useful from these metrics (across all etcd servers):
|
||||
|
||||
* `sum(rate(etcd_proxy_handled_total{job="etcd"}[1m])) by (method)`
|
||||
|
||||
Rate of requests (by HTTP method) handled by all proxies, across a window of `1m`.
|
||||
|
||||
* `histogram_quantile(0.9, sum(rate(handling_duration_seconds{job="etcd",method="GET"}[5m])) by (le))`
|
||||
`histogram_quantile(0.9, sum(rate(handling_duration_seconds{job="etcd",method!="GET"}[5m])) by (le))`
|
||||
|
||||
Show the 0.90-tile latency (in seconds) of handling of user requests across all proxy machines, with a window of `5m`.
|
||||
|
||||
* `sum(rate(etcd_proxy_dropped_total{job="etcd"}[1m])) by (proxying_error)`
|
||||
|
||||
Number of failed request on the proxy. This should be 0, spikes here indicate connectivity issues to the etcd cluster.
|
||||
|
||||
## etcd_debugging namespace metrics
|
||||
|
||||
The metrics under the `etcd_debugging` prefix are for debugging. They are very implementation dependent and volatile. They might be changed or removed without any warning in new etcd releases. Some of the metrics might be moved to the `etcd` prefix when they become more stable.
|
||||
|
||||
### etcdserver
|
||||
|
||||
| Name | Description | Type |
|
||||
|-----------------------------------------|--------------------------------------------------|-----------|
|
||||
| proposal_duration_seconds | The latency distributions of committing proposal | Histogram |
|
||||
| proposals_pending | The current number of pending proposals | Gauge |
|
||||
| proposals_failed_total | The total number of failed proposals | Counter |
|
||||
|
||||
[Proposal][glossary-proposal] duration (`proposal_duration_seconds`) provides a proposal commit latency histogram. The reported latency reflects network and disk IO delays in etcd.
|
||||
|
||||
Proposals pending (`proposals_pending`) indicates how many proposals are queued for commit. Rising pending proposals suggests there is a high client load or the cluster is unstable.
|
||||
|
||||
Failed proposals (`proposals_failed_total`) are normally related to two issues: temporary failures related to a leader election or longer duration downtime caused by a loss of quorum in the cluster.
|
||||
|
||||
### wal
|
||||
|
||||
| Name | Description | Type |
|
||||
|------------------------------------|--------------------------------------------------|-----------|
|
||||
| fsync_duration_seconds | The latency distributions of fsync called by wal | Histogram |
|
||||
| last_index_saved | The index of the last entry saved by wal | Gauge |
|
||||
|
||||
Abnormally high fsync duration (`fsync_duration_seconds`) indicates disk issues and might cause the cluster to be unstable.
|
||||
|
||||
### snapshot
|
||||
|
||||
| Name | Description | Type |
|
||||
|--------------------------------------------|------------------------------------------------------------|-----------|
|
||||
| snapshot_save_total_duration_seconds | The total latency distributions of save called by snapshot | Histogram |
|
||||
|
||||
Abnormally high snapshot duration (`snapshot_save_total_duration_seconds`) indicates disk issues and might cause the cluster to be unstable.
|
||||
|
||||
### rafthttp
|
||||
|
||||
| Name | Description | Type | Labels |
|
||||
|-----------------------------------|--------------------------------------------|--------------|--------------------------------|
|
||||
| message_sent_latency_seconds | The latency distributions of messages sent | HistogramVec | sendingType, msgType, remoteID |
|
||||
| message_sent_failed_total | The total number of failed messages sent | Summary | sendingType, msgType, remoteID |
|
||||
|
||||
|
||||
Abnormally high message duration (`message_sent_latency_seconds`) indicates network issues and might cause the cluster to be unstable.
|
||||
|
||||
An increase in message failures (`message_sent_failed_total`) indicates more severe network issues and might cause the cluster to be unstable.
|
||||
|
||||
Label `sendingType` is the connection type to send messages. `message`, `msgapp` and `msgappv2` use HTTP streaming, while `pipeline` does HTTP request for each message.
|
||||
|
||||
Label `msgType` is the type of raft message. `MsgApp` is log replication messages; `MsgSnap` is snapshot install messages; `MsgProp` is proposal forward messages; the others maintain internal raft status. Given large snapshots, a lengthy msgSnap transmission latency should be expected. For other types of messages, given enough network bandwidth, latencies comparable to ping latency should be expected.
|
||||
|
||||
Label `remoteID` is the member ID of the message destination.
|
||||
|
||||
## Prometheus supplied metrics
|
||||
|
||||
The Prometheus client library provides a number of metrics under the `go` and `process` namespaces. There are a few that are particularly interesting.
|
||||
|
||||
| Name | Description | Type |
|
||||
|-----------------------------------|--------------------------------------------|--------------|
|
||||
| process_open_fds | Number of open file descriptors. | Gauge |
|
||||
| process_max_fds | Maximum number of open file descriptors. | Gauge |
|
||||
|
||||
Heavy file descriptor (`process_open_fds`) usage (i.e., near the process's file descriptor limit, `process_max_fds`) indicates a potential file descriptor exhaustion issue. If the file descriptors are exhausted, etcd may panic because it cannot create new WAL files.
|
||||
|
||||
[glossary-proposal]: glossary.md#proposal
|
||||
[prometheus]: http://prometheus.io/
|
||||
[prometheus-getting-started]: http://prometheus.io/docs/introduction/getting_started/
|
||||
[prometheus-naming]: http://prometheus.io/docs/practices/naming/
|
||||
|
|
@ -1,33 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# Miscellaneous APIs
|
||||
|
||||
* [Getting the etcd version](#getting-the-etcd-version)
|
||||
* [Checking health of an etcd member node](#checking-health-of-an-etcd-member-node)
|
||||
|
||||
## Getting the etcd version
|
||||
|
||||
The etcd version of a specific instance can be obtained from the `/version` endpoint.
|
||||
|
||||
```sh
|
||||
curl -L http://127.0.0.1:2379/version
|
||||
```
|
||||
|
||||
```
|
||||
etcd 2.0.12
|
||||
```
|
||||
|
||||
## Checking health of an etcd member node
|
||||
|
||||
etcd provides a `/health` endpoint to verify the health of a particular member.
|
||||
|
||||
```sh
|
||||
curl http://10.0.0.10:2379/health
|
||||
```
|
||||
|
||||
```json
|
||||
{"health":"true"}
|
||||
```
|
||||
|
|
@ -1,67 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
# FreeBSD
|
||||
|
||||
Starting with version 0.1.2 both etcd and etcdctl have been ported to FreeBSD and can
|
||||
be installed either via packages or ports system. Their versions have been recently
|
||||
updated to 0.2.0 so now you can enjoy using etcd and etcdctl on FreeBSD 10.0 (RC4 as
|
||||
of now) and 9.x where they have been tested. They might also work when installed from
|
||||
ports on earlier versions of FreeBSD, but your mileage may vary.
|
||||
|
||||
## Installation
|
||||
|
||||
### Using pkgng package system
|
||||
|
||||
1. If you do not have pkgng installed, install it with command `pkg` and answering 'Y'
|
||||
when asked
|
||||
|
||||
2. Update your repository data with `pkg update`
|
||||
|
||||
3. Install etcd with `pkg install coreos-etcd coreos-etcdctl`
|
||||
|
||||
4. Verify successful installation with `pkg info | grep etcd` and you should get:
|
||||
|
||||
```
|
||||
r@fbsd10:/ # pkg info | grep etcd
|
||||
coreosetcd0.2.0 Highlyavailable key value store and service discovery
|
||||
coreosetcdctl0.2.0 Simple commandline client for etcd
|
||||
r@fbsd10:/ #
|
||||
```
|
||||
|
||||
5. You’re ready to use etcd and etcdctl! For more information about using pkgng, please
|
||||
see: http://www.freebsd.org/doc/handbook/pkgngintro.html
|
||||
|
||||
### Using ports system
|
||||
|
||||
1. If you do not have ports installed, install with with `portsnap fetch extract` (it
|
||||
may take some time depending on your hardware and network connection)
|
||||
|
||||
2. Build etcd with `cd /usr/ports/devel/etcd && make install clean`, you
|
||||
will get an option to build and install documentation and etcdctl with it.
|
||||
|
||||
3. If you haven't installed it with etcdctl, and you would like to install it later, you can build it
|
||||
with `cd /usr/ports/devel/etcdctl && make install clean`
|
||||
|
||||
4. Verify successful installation with `pkg info | grep etcd` and you should get:
|
||||
|
||||
|
||||
```
|
||||
r@fbsd10:/ # pkg info | grep etcd
|
||||
coreosetcd0.2.0 Highlyavailable key value store and service discovery
|
||||
coreosetcdctl0.2.0 Simple commandline client for etcd
|
||||
r@fbsd10:/ #
|
||||
```
|
||||
|
||||
5. You’re ready to use etcd and etcdctl! For more information about using ports system,
|
||||
please see: https://www.freebsd.org/doc/handbook/portsusing.html
|
||||
|
||||
## Issues
|
||||
|
||||
If you find any issues with the build/install procedure or you've found a problem that
|
||||
you've verified is local to FreeBSD version only (for example, by not being able to
|
||||
reproduce it on any other platform, like OSX or Linux), please sent a
|
||||
problem report using this page for more
|
||||
information: http://www.freebsd.org/sendpr.html
|
||||
|
|
@ -1,56 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# Production Users
|
||||
|
||||
This document tracks people and use cases for etcd in production. By creating a list of production use cases we hope to build a community of advisors that we can reach out to with experience using various etcd applications, operation environments, and cluster sizes. The etcd development team may reach out periodically to check-in on your experience and update this list.
|
||||
|
||||
## discovery.etcd.io
|
||||
|
||||
- *Application*: https://github.com/coreos/discovery.etcd.io
|
||||
- *Launched*: Feb. 2014
|
||||
- *Cluster Size*: 5 members, 5 discovery proxies
|
||||
- *Order of Data Size*: 100s of Megabytes
|
||||
- *Operator*: CoreOS, brandon.philips@coreos.com
|
||||
- *Environment*: AWS
|
||||
- *Backups*: Periodic async to S3
|
||||
|
||||
discovery.etcd.io is the longest continuously running etcd backed service that we know about. It is the basis of automatic cluster bootstrap and was launched in Feb. 2014: https://coreos.com/blog/etcd-0.3.0-released/.
|
||||
|
||||
## OpenTable
|
||||
|
||||
- *Application*: OpenTable internal service discovery and cluster configuration management
|
||||
- *Launched*: May 2014
|
||||
- *Cluster Size*: 3 members each in 6 independent clusters; approximately 50 nodes reading / writing
|
||||
- *Order of Data Size*: 10s of MB
|
||||
- *Operator*: OpenTable, Inc; sschlansker@opentable.com
|
||||
- *Environment*: AWS, VMWare
|
||||
- *Backups*: None, all data can be re-created if necessary.
|
||||
|
||||
## cycoresys.com
|
||||
|
||||
- *Application*: multiple
|
||||
- *Launched*: Jul. 2014
|
||||
- *Cluster Size*: 3 members, _n_ proxies
|
||||
- *Order of Data Size*: 100s of kilobytes
|
||||
- *Operator*: CyCore Systems, Inc, sys@cycoresys.com
|
||||
- *Environment*: Baremetal
|
||||
- *Backups*: Periodic sync to Ceph RadosGW and DigitalOcean VM
|
||||
|
||||
CyCore Systems provides architecture and engineering for computing systems. This cluster provides microservices, virtual machines, databases, storage clusters to a number of clients. It is built on CoreOS machines, with each machine in the cluster running etcd as a peer or proxy.
|
||||
|
||||
## Radius Intelligence
|
||||
|
||||
- *Application*: multiple internal tools, Kubernetes clusters, bootstrappable system configs
|
||||
- *Launched*: June 2015
|
||||
- *Cluster Size*: 2 clusters of 5 and 3 members; approximately a dozen nodes read/write
|
||||
- *Order of Data Size*: 100s of kilobytes
|
||||
- *Operator*: Radius Intelligence; jcderr@radius.com
|
||||
- *Environment*: AWS, CoreOS, Kubernetes
|
||||
- *Backups*: None, all data can be recreated if necessary.
|
||||
|
||||
Radius Intelligence uses Kubernetes running CoreOS to containerize and scale internal toolsets. Examples include running [JetBrains TeamCity][teamcity] and internal AWS security and cost reporting tools. etcd clusters back these clusters as well as provide some basic environment bootstrapping configuration keys.
|
||||
|
||||
[teamcity]: https://www.jetbrains.com/teamcity/
|
||||
|
|
@ -1,158 +0,0 @@
|
|||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
|
||||
# Proxy
|
||||
|
||||
etcd can run as a transparent proxy. Doing so allows for easy discovery of etcd within your infrastructure, since it can run on each machine as a local service. In this mode, etcd acts as a reverse proxy and forwards client requests to an active etcd cluster. The etcd proxy does not participate in the consensus replication of the etcd cluster, thus it neither increases the resilience nor decreases the write performance of the etcd cluster.
|
||||
|
||||
etcd currently supports two proxy modes: `readwrite` and `readonly`. The default mode is `readwrite`, which forwards both read and write requests to the etcd cluster. A `readonly` etcd proxy only forwards read requests to the etcd cluster, and returns `HTTP 501` to all write requests.
|
||||
|
||||
The proxy will shuffle the list of cluster members periodically to avoid sending all connections to a single member.
|
||||
|
||||
The member list used by an etcd proxy consists of all client URLs advertised in the cluster. These client URLs are specified in each etcd cluster member's `advertise-client-urls` option.
|
||||
|
||||
An etcd proxy examines several command-line options to discover its peer URLs. In order of precedence, these options are `discovery`, `discovery-srv`, and `initial-cluster`. The `initial-cluster` option is set to a comma-separated list of one or more etcd peer URLs used temporarily in order to discover the permanent cluster.
|
||||
|
||||
After establishing a list of peer URLs in this manner, the proxy retrieves the list of client URLs from the first reachable peer. These client URLs are specified by the `advertise-client-urls` option to etcd peers. The proxy then continues to connect to the first reachable etcd cluster member every thirty seconds to refresh the list of client URLs.
|
||||
|
||||
While etcd proxies therefore do not need to be given the `advertise-client-urls` option, as they retrieve this configuration from the cluster, this implies that `initial-cluster` must be set correctly for every proxy, and the `advertise-client-urls` option must be set correctly for every non-proxy, first-order cluster peer. Otherwise, requests to any etcd proxy would be forwarded improperly. Take special care not to set the `advertise-client-urls` option to URLs that point to the proxy itself, as such a configuration will cause the proxy to enter a loop, forwarding requests to itself until resources are exhausted. To correct either case, stop etcd and restart it with the correct URLs.
|
||||
|
||||
[This example Procfile][procfile] illustrates the difference in the etcd peer and proxy command lines used to configure and start a cluster with one proxy under the [goreman process management utility][goreman].
|
||||
|
||||
To summarize etcd proxy startup and peer discovery:
|
||||
|
||||
1. etcd proxies execute the following steps in order until the cluster *peer-urls* are known:
|
||||
1. If `discovery` is set for the proxy, ask the given discovery service for
|
||||
the *peer-urls*. The *peer-urls* will be the combined
|
||||
`initial-advertise-peer-urls` of all first-order, non-proxy cluster
|
||||
members.
|
||||
2. If `discovery-srv` is set for the proxy, the *peer-urls* are discovered
|
||||
from DNS.
|
||||
3. If `initial-cluster` is set for the proxy, that will become the value of
|
||||
*peer-urls*.
|
||||
4. Otherwise use the default value of
|
||||
`http://localhost:2380,http://localhost:7001`.
|
||||
2. These *peer-urls* are used to contact the (non-proxy) members of the cluster
|
||||
to find their *client-urls*. The *client-urls* will thus be the combined
|
||||
`advertise-client-urls` of all cluster members (i.e. non-proxies).
|
||||
3. Request of clients of the proxy will be forwarded (proxied) to these
|
||||
*client-urls*.
|
||||
|
||||
Always start the first-order etcd cluster members first, then any proxies. A proxy must be able to reach the cluster members to retrieve its configuration, and will attempt connections somewhat aggressively in the absence of such a channel. Starting the members before any proxy ensures the proxy can discover the client URLs when it later starts.
|
||||
|
||||
## Using an etcd proxy
|
||||
To start etcd in proxy mode, you need to provide three flags: `proxy`, `listen-client-urls`, and `initial-cluster` (or `discovery`).
|
||||
|
||||
To start a readwrite proxy, set `-proxy on`; To start a readonly proxy, set `-proxy readonly`.
|
||||
|
||||
The proxy will be listening on `listen-client-urls` and forward requests to the etcd cluster discovered from in `initial-cluster` or `discovery` url.
|
||||
|
||||
### Start an etcd proxy with a static configuration
|
||||
To start a proxy that will connect to a statically defined etcd cluster, specify the `initial-cluster` flag:
|
||||
|
||||
```
|
||||
etcd --proxy on \
|
||||
--listen-client-urls http://127.0.0.1:2379 \
|
||||
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380
|
||||
```
|
||||
|
||||
### Start an etcd proxy with the discovery service
|
||||
If you bootstrap an etcd cluster using the [discovery service][discovery-service], you can also start the proxy with the same `discovery`.
|
||||
|
||||
To start a proxy using the discovery service, specify the `discovery` flag. The proxy will wait until the etcd cluster defined at the `discovery` url finishes bootstrapping, and then start to forward the requests.
|
||||
|
||||
```
|
||||
etcd --proxy on \
|
||||
--listen-client-urls http://127.0.0.1:2379 \
|
||||
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de \
|
||||
```
|
||||
|
||||
## Fallback to proxy mode with discovery service
|
||||
|
||||
If you bootstrap an etcd cluster using [discovery service][discovery-service] with more than the expected number of etcd members, the extra etcd processes will fall back to being `readwrite` proxies by default. They will forward the requests to the cluster as described above. For example, if you create a discovery url with `size=5`, and start ten etcd processes using that same discovery url, the result will be a cluster with five etcd members and five proxies. Note that this behaviour can be disabled with the `discovery-fallback='exit'` flag.
|
||||
|
||||
## Promote a proxy to a member of etcd cluster
|
||||
|
||||
A Proxy is in the part of etcd cluster that does not participate in consensus. A proxy will not promote itself to an etcd member that participates in consensus automatically in any case.
|
||||
|
||||
If you want to promote a proxy to an etcd member, there are four steps you need to follow:
|
||||
|
||||
- use etcdctl to add the proxy node as an etcd member into the existing cluster
|
||||
- stop the etcd proxy process or service
|
||||
- remove the existing proxy data directory
|
||||
- restart the etcd process with new member configuration
|
||||
|
||||
## Example
|
||||
|
||||
We assume you have a one member etcd cluster with one proxy. The cluster information is listed below:
|
||||
|
||||
|Name|Address|
|
||||
|------|---------|
|
||||
|infra0|10.0.1.10|
|
||||
|proxy0|10.0.1.11|
|
||||
|
||||
This example walks you through a case that you promote one proxy to an etcd member. The cluster will become a two member cluster after finishing the four steps.
|
||||
|
||||
### Add a new member into the existing cluster
|
||||
|
||||
First, use etcdctl to add the member to the cluster, which will output the environment variables need to correctly configure the new member:
|
||||
|
||||
``` bash
|
||||
$ etcdctl -endpoint http://10.0.1.10:2379 member add infra1 http://10.0.1.11:2380
|
||||
added member 9bf1b35fc7761a23 to cluster
|
||||
|
||||
ETCD_NAME="infra1"
|
||||
ETCD_INITIAL_CLUSTER="infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380"
|
||||
ETCD_INITIAL_CLUSTER_STATE=existing
|
||||
```
|
||||
|
||||
### Stop the proxy process
|
||||
|
||||
Stop the existing proxy so we can wipe its state on disk and reload it with the new configuration:
|
||||
|
||||
``` bash
|
||||
ps aux | grep etcd
|
||||
kill %etcd_proxy_pid%
|
||||
```
|
||||
|
||||
or (if you are running etcd proxy as etcd service under systemd)
|
||||
|
||||
``` bash
|
||||
sudo systemctl stop etcd
|
||||
```
|
||||
|
||||
### Remove the existing proxy data dir
|
||||
|
||||
``` bash
|
||||
rm -rf %data_dir%/proxy
|
||||
```
|
||||
|
||||
### Start etcd as a new member
|
||||
|
||||
Finally, start the reconfigured member and make sure it joins the cluster correctly:
|
||||
|
||||
``` bash
|
||||
$ export ETCD_NAME="infra1"
|
||||
$ export ETCD_INITIAL_CLUSTER="infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380"
|
||||
$ export ETCD_INITIAL_CLUSTER_STATE=existing
|
||||
$ etcd --listen-client-urls http://10.0.1.11:2379 \
|
||||
--advertise-client-urls http://10.0.1.11:2379 \
|
||||
--listen-peer-urls http://10.0.1.11:2380 \
|
||||
--initial-advertise-peer-urls http://10.0.1.11:2380 \
|
||||
--data-dir %data_dir%
|
||||
```
|
||||
|
||||
If you are running etcd under systemd, you should modify the service file with correct configuration and restart the service:
|
||||
|
||||
``` bash
|
||||
sudo systemd restart etcd
|
||||
```
|
||||
|
||||
If an error occurs, check the [add member troubleshooting doc][runtime-configuration].
|
||||
|
||||
[discovery-service]: clustering.md#discovery
|
||||
[goreman]: https://github.com/mattn/goreman
|
||||
[procfile]: https://github.com/etcd-io/etcd/blob/master/Procfile.v2
|
||||
[runtime-configuration]: runtime-configuration.md#error-cases-when-adding-members
|
||||
|
|
@ -1,51 +0,0 @@
|
|||
---
|
||||
title: Reporting Bugs
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
If you find bugs or documentation mistakes in the etcd project, please let us know by [opening an issue][etcd-issue]. We treat bugs and mistakes very seriously and believe no issue is too small. Before creating a bug report, please check that an issue reporting the same problem does not already exist.
|
||||
|
||||
To make your bug report accurate and easy to understand, please try to create bug reports that are:
|
||||
|
||||
- Specific. Include as much details as possible: which version, what environment, what configuration, etc. You can also attach etcd log (the starting log with etcd configuration is especially important).
|
||||
|
||||
- Reproducible. Include the steps to reproduce the problem. We understand some issues might be hard to reproduce, please includes the steps that might lead to the problem. You can also attach the affected etcd data dir and stack strace to the bug report.
|
||||
|
||||
- Isolated. Please try to isolate and reproduce the bug with minimum dependencies. It would significantly slow down the speed to fix a bug if too many dependencies are involved in a bug report. Debugging external systems that rely on etcd is out of scope, but we are happy to point you in the right direction or help you interact with etcd in the correct manner.
|
||||
|
||||
- Unique. Do not duplicate existing bug report.
|
||||
|
||||
- Scoped. One bug per report. Do not follow up with another bug inside one report.
|
||||
|
||||
You might also want to read [Elika Etemad’s article on filing good bug reports][filing-good-bugs] before creating a bug report.
|
||||
|
||||
We might ask you for further information to locate a bug. A duplicated bug report will be closed.
|
||||
|
||||
## Frequently Asked Questions
|
||||
|
||||
### How to get a stack trace
|
||||
|
||||
``` bash
|
||||
$ kill -QUIT $PID
|
||||
```
|
||||
|
||||
### How to get etcd version
|
||||
|
||||
``` bash
|
||||
$ etcd --version
|
||||
```
|
||||
|
||||
### How to get etcd configuration and log when it runs as systemd service ‘etcd2.service’
|
||||
|
||||
``` bash
|
||||
$ sudo systemctl cat etcd2
|
||||
$ sudo journalctl -u etcd2
|
||||
```
|
||||
|
||||
Due to an upstream systemd bug, journald may miss the last few log lines when its process exit. If journalctl tells you that etcd stops without fatal or panic message, you could try `sudo journalctl -f -t etcd2` to get full log.
|
||||
|
||||
[etcd-issue]: https://github.com/etcd-io/etcd/issues/new
|
||||
[filing-good-bugs]: http://fantasai.inkedblade.net/style/talks/filing-good-bugs/
|
||||
|
|
@ -1,220 +0,0 @@
|
|||
---
|
||||
title: etcd v3 API
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../../docs.md#documentation
|
||||
|
||||
|
||||
# Overview
|
||||
|
||||
The etcd v3 API is designed to give users a more efficient and cleaner abstraction compared to etcd v2. There are a number of semantic and protocol changes in this new API. For an overview [see Xiang Li's video](https://youtu.be/J5AioGtEPeQ?t=211).
|
||||
|
||||
To prove out the design of the v3 API the team has also built [a number of example recipes](https://github.com/coreos/etcd/tree/master/contrib/recipes), there is a [video discussing these recipes too](https://www.youtube.com/watch?v=fj-2RY-3yVU&feature=youtu.be&t=590).
|
||||
|
||||
# Design
|
||||
|
||||
1. Flatten binary key-value space
|
||||
|
||||
2. Keep the event history until compaction
|
||||
- access to old version of keys
|
||||
- user controlled history compaction
|
||||
|
||||
3. Support range query
|
||||
- Pagination support with limit argument
|
||||
- Support consistency guarantee across multiple range queries
|
||||
|
||||
4. Replace TTL key with Lease
|
||||
- more efficient/ low cost keep alive
|
||||
- a logical group of TTL keys
|
||||
|
||||
5. Replace CAS/CAD with multi-object Txn
|
||||
- MUCH MORE powerful and flexible
|
||||
|
||||
6. Support efficient watching with multiple ranges
|
||||
|
||||
7. RPC API supports the completed set of APIs.
|
||||
- more efficient than JSON/HTTP
|
||||
- additional txn/lease support
|
||||
|
||||
8. HTTP API supports a subset of APIs.
|
||||
- easy for people to try out etcd
|
||||
- easy for people to write simple etcd application
|
||||
|
||||
|
||||
## Notes
|
||||
|
||||
### Request Size Limitation
|
||||
|
||||
The max request size is around 1MB. Since etcd replicates requests in a streaming fashion, a very large
|
||||
request might block other requests for a long time. The use case for etcd is to store small configuration
|
||||
values, so we prevent user from submitting large requests. This also applies to Txn requests. We might loosen
|
||||
the size in the future a little bit or make it configurable.
|
||||
|
||||
## Protobuf Defined API
|
||||
|
||||
[api protobuf][api-protobuf]
|
||||
|
||||
[kv protobuf][kv-protobuf]
|
||||
|
||||
## Examples
|
||||
|
||||
### Put a key (foo=bar)
|
||||
```
|
||||
// A put is always successful
|
||||
Put( PutRequest { key = foo, value = bar } )
|
||||
|
||||
PutResponse {
|
||||
cluster_id = 0x1000,
|
||||
member_id = 0x1,
|
||||
revision = 1,
|
||||
raft_term = 0x1,
|
||||
}
|
||||
```
|
||||
|
||||
### Get a key (assume we have foo=bar)
|
||||
```
|
||||
Get ( RangeRequest { key = foo } )
|
||||
|
||||
RangeResponse {
|
||||
cluster_id = 0x1000,
|
||||
member_id = 0x1,
|
||||
revision = 1,
|
||||
raft_term = 0x1,
|
||||
kvs = {
|
||||
{
|
||||
key = foo,
|
||||
value = bar,
|
||||
create_revision = 1,
|
||||
mod_revision = 1,
|
||||
version = 1;
|
||||
},
|
||||
},
|
||||
}
|
||||
```
|
||||
|
||||
### Range over a key space (assume we have foo0=bar0… foo100=bar100)
|
||||
```
|
||||
Range ( RangeRequest { key = foo, end_key = foo80, limit = 30 } )
|
||||
|
||||
RangeResponse {
|
||||
cluster_id = 0x1000,
|
||||
member_id = 0x1,
|
||||
revision = 100,
|
||||
raft_term = 0x1,
|
||||
kvs = {
|
||||
{
|
||||
key = foo0,
|
||||
value = bar0,
|
||||
create_revision = 1,
|
||||
mod_revision = 1,
|
||||
version = 1;
|
||||
},
|
||||
...,
|
||||
{
|
||||
key = foo30,
|
||||
value = bar30,
|
||||
create_revision = 30,
|
||||
mod_revision = 30,
|
||||
version = 1;
|
||||
},
|
||||
},
|
||||
}
|
||||
```
|
||||
|
||||
### Finish a txn (assume we have foo0=bar0, foo1=bar1)
|
||||
```
|
||||
Txn(TxnRequest {
|
||||
// mod_revision of foo0 is equal to 1, mod_revision of foo1 is greater than 1
|
||||
compare = {
|
||||
{compareType = equal, key = foo0, mod_revision = 1},
|
||||
{compareType = greater, key = foo1, mod_revision = 1}}
|
||||
},
|
||||
// if the comparison succeeds, put foo2 = bar2
|
||||
success = {PutRequest { key = foo2, value = success }},
|
||||
// if the comparison fails, put foo2=fail
|
||||
failure = {PutRequest { key = foo2, value = failure }},
|
||||
)
|
||||
|
||||
TxnResponse {
|
||||
cluster_id = 0x1000,
|
||||
member_id = 0x1,
|
||||
revision = 3,
|
||||
raft_term = 0x1,
|
||||
succeeded = true,
|
||||
responses = {
|
||||
// response of PUT foo2=success
|
||||
{
|
||||
cluster_id = 0x1000,
|
||||
member_id = 0x1,
|
||||
revision = 3,
|
||||
raft_term = 0x1,
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Watch on a key/range
|
||||
|
||||
```
|
||||
Watch( WatchRequest{
|
||||
key = foo,
|
||||
end_key = fop, // prefix foo
|
||||
start_revision = 20,
|
||||
end_revision = 10000,
|
||||
// server decided notification frequency
|
||||
progress_notification = true,
|
||||
}
|
||||
… // this can be a watch request stream
|
||||
)
|
||||
|
||||
// put (foo0=bar0) event at 3
|
||||
WatchResponse {
|
||||
cluster_id = 0x1000,
|
||||
member_id = 0x1,
|
||||
revision = 3,
|
||||
raft_term = 0x1,
|
||||
event_type = put,
|
||||
kv = {
|
||||
key = foo0,
|
||||
value = bar0,
|
||||
create_revision = 1,
|
||||
mod_revision = 1,
|
||||
version = 1;
|
||||
},
|
||||
}
|
||||
…
|
||||
|
||||
// a notification at 2000
|
||||
WatchResponse {
|
||||
cluster_id = 0x1000,
|
||||
member_id = 0x1,
|
||||
revision = 2000,
|
||||
raft_term = 0x1,
|
||||
// nil event as notification
|
||||
}
|
||||
|
||||
…
|
||||
|
||||
// put (foo0=bar3000) event at 3000
|
||||
WatchResponse {
|
||||
cluster_id = 0x1000,
|
||||
member_id = 0x1,
|
||||
revision = 3000,
|
||||
raft_term = 0x1,
|
||||
event_type = put,
|
||||
kv = {
|
||||
key = foo0,
|
||||
value = bar3000,
|
||||
create_revision = 1,
|
||||
mod_revision = 3000,
|
||||
version = 2;
|
||||
},
|
||||
}
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
[api-protobuf]: https://github.com/coreos/etcd/blob/release-2.3/etcdserver/etcdserverpb/rpc.proto
|
||||
[kv-protobuf]: https://github.com/coreos/etcd/blob/release-2.3/storage/storagepb/kv.proto
|
||||
|
|
@ -1,190 +0,0 @@
|
|||
---
|
||||
title: Runtime Reconfiguration
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
etcd comes with support for incremental runtime reconfiguration, which allows users to update the membership of the cluster at run time.
|
||||
|
||||
Reconfiguration requests can only be processed when the majority of the cluster members are functioning. It is **highly recommended** to always have a cluster size greater than two in production. It is unsafe to remove a member from a two member cluster. The majority of a two member cluster is also two. If there is a failure during the removal process, the cluster might not able to make progress and need to [restart from majority failure][majority failure].
|
||||
|
||||
To better understand the design behind runtime reconfiguration, we suggest you read [the runtime reconfiguration document][runtime-reconf].
|
||||
|
||||
## Reconfiguration Use Cases
|
||||
|
||||
Let's walk through some common reasons for reconfiguring a cluster. Most of these just involve combinations of adding or removing a member, which are explained below under [Cluster Reconfiguration Operations][cluster-reconf].
|
||||
|
||||
### Cycle or Upgrade Multiple Machines
|
||||
|
||||
If you need to move multiple members of your cluster due to planned maintenance (hardware upgrades, network downtime, etc.), it is recommended to modify members one at a time.
|
||||
|
||||
It is safe to remove the leader, however there is a brief period of downtime while the election process takes place. If your cluster holds more than 50MB, it is recommended to [migrate the member's data directory][member migration].
|
||||
|
||||
### Change the Cluster Size
|
||||
|
||||
Increasing the cluster size can enhance [failure tolerance][fault tolerance table] and provide better read performance. Since clients can read from any member, increasing the number of members increases the overall read throughput.
|
||||
|
||||
Decreasing the cluster size can improve the write performance of a cluster, with a trade-off of decreased resilience. Writes into the cluster are replicated to a majority of members of the cluster before considered committed. Decreasing the cluster size lowers the majority, and each write is committed more quickly.
|
||||
|
||||
### Replace A Failed Machine
|
||||
|
||||
If a machine fails due to hardware failure, data directory corruption, or some other fatal situation, it should be replaced as soon as possible. Machines that have failed but haven't been removed adversely affect your quorum and reduce the tolerance for an additional failure.
|
||||
|
||||
To replace the machine, follow the instructions for [removing the member][remove member] from the cluster, and then [add a new member][add member] in its place. If your cluster holds more than 50MB, it is recommended to [migrate the failed member's data directory][member migration] if you can still access it.
|
||||
|
||||
### Restart Cluster from Majority Failure
|
||||
|
||||
If the majority of your cluster is lost or all of your nodes have changed IP addresses, then you need to take manual action in order to recover safely.
|
||||
The basic steps in the recovery process include [creating a new cluster using the old data][disaster recovery], forcing a single member to act as the leader, and finally using runtime configuration to [add new members][add member] to this new cluster one at a time.
|
||||
|
||||
## Cluster Reconfiguration Operations
|
||||
|
||||
Now that we have the use cases in mind, let us lay out the operations involved in each.
|
||||
|
||||
Before making any change, the simple majority (quorum) of etcd members must be available.
|
||||
This is essentially the same requirement as for any other write to etcd.
|
||||
|
||||
All changes to the cluster are done one at a time:
|
||||
|
||||
* To update a single member peerURLs you will make an update operation
|
||||
* To replace a single member you will make an add then a remove operation
|
||||
* To increase from 3 to 5 members you will make two add operations
|
||||
* To decrease from 5 to 3 you will make two remove operations
|
||||
|
||||
All of these examples will use the `etcdctl` command line tool that ships with etcd.
|
||||
If you want to use the members API directly you can find the documentation [here][member-api].
|
||||
|
||||
### Update a Member
|
||||
|
||||
#### Update advertise client URLs
|
||||
|
||||
If you would like to update the advertise client URLs of a member, you can simply restart
|
||||
that member with updated client urls flag (`--advertise-client-urls`) or environment variable
|
||||
(`ETCD_ADVERTISE_CLIENT_URLS`). The restarted member will self publish the updated URLs.
|
||||
A wrongly updated client URL will not affect the health of the etcd cluster.
|
||||
|
||||
#### Update advertise peer URLs
|
||||
|
||||
If you would like to update the advertise peer URLs of a member, you have to first update
|
||||
it explicitly via member command and then restart the member. The additional action is required
|
||||
since updating peer URLs changes the cluster wide configuration and can affect the health of the etcd cluster.
|
||||
|
||||
To update the peer URLs, first, we need to find the target member's ID. You can list all members with `etcdctl`:
|
||||
|
||||
```sh
|
||||
$ etcdctl member list
|
||||
6e3bd23ae5f1eae0: name=node2 peerURLs=http://localhost:23802 clientURLs=http://127.0.0.1:23792
|
||||
924e2e83e93f2560: name=node3 peerURLs=http://localhost:23803 clientURLs=http://127.0.0.1:23793
|
||||
a8266ecf031671f3: name=node1 peerURLs=http://localhost:23801 clientURLs=http://127.0.0.1:23791
|
||||
```
|
||||
|
||||
In this example let's `update` a8266ecf031671f3 member ID and change its peerURLs value to http://10.0.1.10:2380
|
||||
|
||||
```sh
|
||||
$ etcdctl member update a8266ecf031671f3 http://10.0.1.10:2380
|
||||
Updated member with ID a8266ecf031671f3 in cluster
|
||||
```
|
||||
|
||||
### Remove a Member
|
||||
|
||||
Let us say the member ID we want to remove is a8266ecf031671f3.
|
||||
We then use the `remove` command to perform the removal:
|
||||
|
||||
```sh
|
||||
$ etcdctl member remove a8266ecf031671f3
|
||||
Removed member a8266ecf031671f3 from cluster
|
||||
```
|
||||
|
||||
The target member will stop itself at this point and print out the removal in the log:
|
||||
|
||||
```
|
||||
etcd: this member has been permanently removed from the cluster. Exiting.
|
||||
```
|
||||
|
||||
It is safe to remove the leader, however the cluster will be inactive while a new leader is elected. This duration is normally the period of election timeout plus the voting process.
|
||||
|
||||
### Add a New Member
|
||||
|
||||
Adding a member is a two step process:
|
||||
|
||||
* Add the new member to the cluster via the [members API][member-api] or the `etcdctl member add` command.
|
||||
* Start the new member with the new cluster configuration, including a list of the updated members (existing members + the new member).
|
||||
|
||||
Using `etcdctl` let's add the new member to the cluster by specifying its [name][conf-name] and [advertised peer URLs][conf-adv-peer]:
|
||||
|
||||
```sh
|
||||
$ etcdctl member add infra3 http://10.0.1.13:2380
|
||||
added member 9bf1b35fc7761a23 to cluster
|
||||
|
||||
ETCD_NAME="infra3"
|
||||
ETCD_INITIAL_CLUSTER="infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380,infra3=http://10.0.1.13:2380"
|
||||
ETCD_INITIAL_CLUSTER_STATE=existing
|
||||
```
|
||||
|
||||
`etcdctl` has informed the cluster about the new member and printed out the environment variables needed to successfully start it.
|
||||
Now start the new etcd process with the relevant flags for the new member:
|
||||
|
||||
```sh
|
||||
$ export ETCD_NAME="infra3"
|
||||
$ export ETCD_INITIAL_CLUSTER="infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380,infra3=http://10.0.1.13:2380"
|
||||
$ export ETCD_INITIAL_CLUSTER_STATE=existing
|
||||
$ etcd -listen-client-urls http://10.0.1.13:2379 -advertise-client-urls http://10.0.1.13:2379 -listen-peer-urls http://10.0.1.13:2380 -initial-advertise-peer-urls http://10.0.1.13:2380 -data-dir %data_dir%
|
||||
```
|
||||
|
||||
The new member will run as a part of the cluster and immediately begin catching up with the rest of the cluster.
|
||||
|
||||
If you are adding multiple members the best practice is to configure a single member at a time and verify it starts correctly before adding more new members.
|
||||
If you add a new member to a 1-node cluster, the cluster cannot make progress before the new member starts because it needs two members as majority to agree on the consensus. You will only see this behavior between the time `etcdctl member add` informs the cluster about the new member and the new member successfully establishing a connection to the existing one.
|
||||
|
||||
#### Error Cases When Adding Members
|
||||
|
||||
In the following case we have not included our new host in the list of enumerated nodes.
|
||||
If this is a new cluster, the node must be added to the list of initial cluster members.
|
||||
|
||||
```sh
|
||||
$ etcd -name infra3 \
|
||||
-initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
|
||||
-initial-cluster-state existing
|
||||
etcdserver: assign ids error: the member count is unequal
|
||||
exit 1
|
||||
```
|
||||
|
||||
In this case we give a different address (10.0.1.14:2380) to the one that we used to join the cluster (10.0.1.13:2380).
|
||||
|
||||
```sh
|
||||
$ etcd -name infra4 \
|
||||
-initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380,infra4=http://10.0.1.14:2380 \
|
||||
-initial-cluster-state existing
|
||||
etcdserver: assign ids error: unmatched member while checking PeerURLs
|
||||
exit 1
|
||||
```
|
||||
|
||||
When we start etcd using the data directory of a removed member, etcd will exit automatically if it connects to any active member in the cluster:
|
||||
|
||||
```sh
|
||||
$ etcd
|
||||
etcd: this member has been permanently removed from the cluster. Exiting.
|
||||
exit 1
|
||||
```
|
||||
|
||||
### Strict Reconfiguration Check Mode (`-strict-reconfig-check`)
|
||||
|
||||
As described in the above, the best practice of adding new members is to configure a single member at a time and verify it starts correctly before adding more new members. This step by step approach is very important because if newly added members is not configured correctly (for example the peer URLs are incorrect), the cluster can lose quorum. The quorum loss happens since the newly added member are counted in the quorum even if that member is not reachable from other existing members. Also quorum loss might happen if there is a connectivity issue or there are operational issues.
|
||||
|
||||
For avoiding this problem, etcd provides an option `-strict-reconfig-check`. If this option is passed to etcd, etcd rejects reconfiguration requests if the number of started members will be less than a quorum of the reconfigured cluster.
|
||||
|
||||
It is recommended to enable this option. However, it is disabled by default because of keeping compatibility.
|
||||
|
||||
[add member]: #add-a-new-member
|
||||
[cluster-reconf]: #cluster-reconfiguration-operations
|
||||
[conf-adv-peer]: configuration.md#-initial-advertise-peer-urls
|
||||
[conf-name]: configuration.md#-name
|
||||
[disaster recovery]: admin_guide.md#disaster-recovery
|
||||
[fault tolerance table]: admin_guide.md#fault-tolerance-table
|
||||
[majority failure]: #restart-cluster-from-majority-failure
|
||||
[member-api]: members_api.md
|
||||
[member migration]: admin_guide.md#member-migration
|
||||
[remove member]: #remove-a-member
|
||||
[runtime-reconf]: runtime-reconf-design.md
|
||||
|
|
@ -1,56 +0,0 @@
|
|||
---
|
||||
title: Design of Runtime Reconfiguration
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
Runtime reconfiguration is one of the hardest and most error prone features in a distributed system, especially in a consensus based system like etcd.
|
||||
|
||||
Read on to learn about the design of etcd's runtime reconfiguration commands and how we tackled these problems.
|
||||
|
||||
## Two Phase Config Changes Keep you Safe
|
||||
|
||||
In etcd, every runtime reconfiguration has to go through [two phases][add-member] for safety reasons. For example, to add a member you need to first inform cluster of new configuration and then start the new member.
|
||||
|
||||
Phase 1 - Inform cluster of new configuration
|
||||
|
||||
To add a member into etcd cluster, you need to make an API call to request a new member to be added to the cluster. And this is the only way that you can add a new member into an existing cluster. The API call returns when the cluster agrees on the configuration change.
|
||||
|
||||
Phase 2 - Start new member
|
||||
|
||||
To join the new etcd member into the existing cluster, you need to specify the correct `initial-cluster` and set `initial-cluster-state` to `existing`. When the member starts, it will contact the existing cluster first and verify the current cluster configuration matches the expected one specified in `initial-cluster`. When the new member successfully starts, you know your cluster reached the expected configuration.
|
||||
|
||||
By splitting the process into two discrete phases users are forced to be explicit regarding cluster membership changes. This actually gives users more flexibility and makes things easier to reason about. For example, if there is an attempt to add a new member with the same ID as an existing member in an etcd cluster, the action will fail immediately during phase one without impacting the running cluster. Similar protection is provided to prevent adding new members by mistake. If a new etcd member attempts to join the cluster before the cluster has accepted the configuration change, it will not be accepted by the cluster.
|
||||
|
||||
Without the explicit workflow around cluster membership etcd would be vulnerable to unexpected cluster membership changes. For example, if etcd is running under an init system such as systemd, etcd would be restarted after being removed via the membership API, and attempt to rejoin the cluster on startup. This cycle would continue every time a member is removed via the API and systemd is set to restart etcd after failing, which is unexpected.
|
||||
|
||||
We think runtime reconfiguration should be a low frequent operation. We made the decision to keep it explicit and user-driven to ensure configuration safety and keep your cluster always running smoothly under your control.
|
||||
|
||||
## Permanent Loss of Quorum Requires New Cluster
|
||||
|
||||
If a cluster permanently loses a majority of its members, a new cluster will need to be started from an old data directory to recover the previous state.
|
||||
|
||||
It is entirely possible to force removing the failed members from the existing cluster to recover. However, we decided not to support this method since it bypasses the normal consensus committing phase, which is unsafe. If the member to remove is not actually dead or you force to remove different members through different members in the same cluster, you will end up with diverged cluster with same clusterID. This is very dangerous and hard to debug/fix afterwards.
|
||||
|
||||
If you have a correct deployment, the possibility of permanent majority lose is very low. But it is a severe enough problem that worth special care. We strongly suggest you to read the [disaster recovery documentation][disaster-recovery] and prepare for permanent majority lose before you put etcd into production.
|
||||
|
||||
## Do Not Use Public Discovery Service For Runtime Reconfiguration
|
||||
|
||||
The public discovery service should only be used for bootstrapping a cluster. To join member into an existing cluster, you should use runtime reconfiguration API.
|
||||
|
||||
Discovery service is designed for bootstrapping an etcd cluster in the cloud environment, when you do not know the IP addresses of all the members beforehand. After you successfully bootstrap a cluster, the IP addresses of all the members are known. Technically, you should not need the discovery service any more.
|
||||
|
||||
It seems that using public discovery service is a convenient way to do runtime reconfiguration, after all discovery service already has all the cluster configuration information. However relying on public discovery service brings troubles:
|
||||
|
||||
1. it introduces external dependencies for the entire life-cycle of your cluster, not just bootstrap time. If there is a network issue between your cluster and public discovery service, your cluster will suffer from it.
|
||||
|
||||
2. public discovery service must reflect correct runtime configuration of your cluster during it life-cycle. It has to provide security mechanism to avoid bad actions, and it is hard.
|
||||
|
||||
3. public discovery service has to keep tens of thousands of cluster configurations. Our public discovery service backend is not ready for that workload.
|
||||
|
||||
If you want to have a discovery service that supports runtime reconfiguration, the best choice is to build your private one.
|
||||
|
||||
[add-member]: runtime-configuration.md#add-a-new-member
|
||||
[disaster-recovery]: admin_guide.md#disaster-recovery
|
||||
|
|
@ -1,200 +0,0 @@
|
|||
---
|
||||
title: Security Model
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
etcd supports SSL/TLS as well as authentication through client certificates, both for clients to server as well as peer (server to server / cluster) communication.
|
||||
|
||||
To get up and running you first need to have a CA certificate and a signed key pair for one member. It is recommended to create and sign a new key pair for every member in a cluster.
|
||||
|
||||
For convenience, the [cfssl] tool provides an easy interface to certificate generation, and we provide an example using the tool [here][tls-setup]. You can also examine this [alternative guide to generating self-signed key pairs][tls-guide].
|
||||
|
||||
## Basic setup
|
||||
|
||||
etcd takes several certificate related configuration options, either through command-line flags or environment variables:
|
||||
|
||||
**Client-to-server communication:**
|
||||
|
||||
`--cert-file=<path>`: Certificate used for SSL/TLS connections **to** etcd. When this option is set, you can set advertise-client-urls using HTTPS schema.
|
||||
|
||||
`--key-file=<path>`: Key for the certificate. Must be unencrypted.
|
||||
|
||||
`--client-cert-auth`: When this is set etcd will check all incoming HTTPS requests for a client certificate signed by the trusted CA, requests that don't supply a valid client certificate will fail. If [authentication][auth] is enabled, the certificate provides credentials for the user name given by the Common Name field.
|
||||
|
||||
`--trusted-ca-file=<path>`: Trusted certificate authority.
|
||||
|
||||
**Peer (server-to-server / cluster) communication:**
|
||||
|
||||
The peer options work the same way as the client-to-server options:
|
||||
|
||||
`--peer-cert-file=<path>`: Certificate used for SSL/TLS connections between peers. This will be used both for listening on the peer address as well as sending requests to other peers.
|
||||
|
||||
`--peer-key-file=<path>`: Key for the certificate. Must be unencrypted.
|
||||
|
||||
`--peer-client-cert-auth`: When set, etcd will check all incoming peer requests from the cluster for valid client certificates signed by the supplied CA.
|
||||
|
||||
`--peer-trusted-ca-file=<path>`: Trusted certificate authority.
|
||||
|
||||
If either a client-to-server or peer certificate is supplied the key must also be set. All of these configuration options are also available through the environment variables, `ETCD_CA_FILE`, `ETCD_PEER_CA_FILE` and so on.
|
||||
|
||||
## Example 1: Client-to-server transport security with HTTPS
|
||||
|
||||
For this you need your CA certificate (`ca.crt`) and signed key pair (`server.crt`, `server.key`) ready.
|
||||
|
||||
Let us configure etcd to provide simple HTTPS transport security step by step:
|
||||
|
||||
```sh
|
||||
$ etcd -name infra0 -data-dir infra0 \
|
||||
-cert-file=/path/to/server.crt -key-file=/path/to/server.key \
|
||||
-advertise-client-urls=https://127.0.0.1:2379 -listen-client-urls=https://127.0.0.1:2379
|
||||
```
|
||||
|
||||
This should start up fine and you can now test the configuration by speaking HTTPS to etcd:
|
||||
|
||||
```sh
|
||||
$ curl --cacert /path/to/ca.crt https://127.0.0.1:2379/v2/keys/foo -XPUT -d value=bar -v
|
||||
```
|
||||
|
||||
You should be able to see the handshake succeed. Because we use self-signed certificates with our own certificate authorities you need to provide the CA to curl using the `--cacert` option. Another possibility would be to add your CA certificate to the trusted certificates on your system (usually in `/etc/ssl/certs`).
|
||||
|
||||
**OSX 10.9+ Users**: curl 7.30.0 on OSX 10.9+ doesn't understand certificates passed in on the command line.
|
||||
Instead you must import the dummy ca.crt directly into the keychain or add the `-k` flag to curl to ignore errors.
|
||||
If you want to test without the `-k` flag run `open ./fixtures/ca/ca.crt` and follow the prompts.
|
||||
Please remove this certificate after you are done testing!
|
||||
If you know of a workaround let us know.
|
||||
|
||||
## Example 2: Client-to-server authentication with HTTPS client certificates
|
||||
|
||||
For now we've given the etcd client the ability to verify the server identity and provide transport security. We can however also use client certificates to prevent unauthorized access to etcd.
|
||||
|
||||
The clients will provide their certificates to the server and the server will check whether the cert is signed by the supplied CA and decide whether to serve the request.
|
||||
|
||||
You need the same files mentioned in the first example for this, as well as a key pair for the client (`client.crt`, `client.key`) signed by the same certificate authority.
|
||||
|
||||
```sh
|
||||
$ etcd -name infra0 -data-dir infra0 \
|
||||
-client-cert-auth -trusted-ca-file=/path/to/ca.crt -cert-file=/path/to/server.crt -key-file=/path/to/server.key \
|
||||
-advertise-client-urls https://127.0.0.1:2379 -listen-client-urls https://127.0.0.1:2379
|
||||
```
|
||||
|
||||
Now try the same request as above to this server:
|
||||
|
||||
```sh
|
||||
$ curl --cacert /path/to/ca.crt https://127.0.0.1:2379/v2/keys/foo -XPUT -d value=bar -v
|
||||
```
|
||||
|
||||
The request should be rejected by the server:
|
||||
|
||||
```
|
||||
...
|
||||
routines:SSL3_READ_BYTES:sslv3 alert bad certificate
|
||||
...
|
||||
```
|
||||
|
||||
To make it succeed, we need to give the CA signed client certificate to the server:
|
||||
|
||||
```sh
|
||||
$ curl --cacert /path/to/ca.crt --cert /path/to/client.crt --key /path/to/client.key \
|
||||
-L https://127.0.0.1:2379/v2/keys/foo -XPUT -d value=bar -v
|
||||
```
|
||||
|
||||
You should be able to see:
|
||||
|
||||
```
|
||||
...
|
||||
SSLv3, TLS handshake, CERT verify (15):
|
||||
...
|
||||
TLS handshake, Finished (20)
|
||||
```
|
||||
|
||||
And also the response from the server:
|
||||
|
||||
```json
|
||||
{
|
||||
"action": "set",
|
||||
"node": {
|
||||
"createdIndex": 12,
|
||||
"key": "/foo",
|
||||
"modifiedIndex": 12,
|
||||
"value": "bar"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Example 3: Transport security & client certificates in a cluster
|
||||
|
||||
etcd supports the same model as above for **peer communication**, that means the communication between etcd members in a cluster.
|
||||
|
||||
Assuming we have our `ca.crt` and two members with their own keypairs (`member1.crt` & `member1.key`, `member2.crt` & `member2.key`) signed by this CA, we launch etcd as follows:
|
||||
|
||||
|
||||
```sh
|
||||
DISCOVERY_URL=... # from https://discovery.etcd.io/new
|
||||
|
||||
# member1
|
||||
$ etcd -name infra1 -data-dir infra1 \
|
||||
-peer-client-cert-auth -peer-trusted-ca-file=/path/to/ca.crt -peer-cert-file=/path/to/member1.crt -peer-key-file=/path/to/member1.key \
|
||||
-initial-advertise-peer-urls=https://10.0.1.10:2380 -listen-peer-urls=https://10.0.1.10:2380 \
|
||||
-discovery ${DISCOVERY_URL}
|
||||
|
||||
# member2
|
||||
$ etcd -name infra2 -data-dir infra2 \
|
||||
-peer-client-cert-auth -peer-trusted-ca-file=/path/to/ca.crt -peer-cert-file=/path/to/member2.crt -peer-key-file=/path/to/member2.key \
|
||||
-initial-advertise-peer-urls=https://10.0.1.11:2380 -listen-peer-urls=https://10.0.1.11:2380 \
|
||||
-discovery ${DISCOVERY_URL}
|
||||
```
|
||||
|
||||
The etcd members will form a cluster and all communication between members in the cluster will be encrypted and authenticated using the client certificates. You will see in the output of etcd that the addresses it connects to use HTTPS.
|
||||
|
||||
## Notes For etcd Proxy
|
||||
|
||||
etcd proxy terminates the TLS from its client if the connection is secure, and uses proxy's own key/cert specified in `--peer-key-file` and `--peer-cert-file` to communicate with etcd members.
|
||||
|
||||
The proxy communicates with etcd members through both the `--advertise-client-urls` and `--advertise-peer-urls` of a given member. It forwards client requests to etcd members’ advertised client urls, and it syncs the initial cluster configuration through etcd members’ advertised peer urls.
|
||||
|
||||
When client authentication is enabled for an etcd member, the administrator must ensure that the peer certificate specified in the proxy's `--peer-cert-file` option is valid for that authentication. The proxy's peer certificate must also be valid for peer authentication if peer authentication is enabled.
|
||||
|
||||
## Frequently Asked Questions
|
||||
|
||||
### My cluster is not working with peer tls configuration?
|
||||
|
||||
The internal protocol of etcd v2.0.x uses a lot of short-lived HTTP connections.
|
||||
So, when enabling TLS you may need to increase the heartbeat interval and election timeouts to reduce internal cluster connection churn.
|
||||
A reasonable place to start are these values: ` --heartbeat-interval 500 --election-timeout 2500`.
|
||||
These issues are resolved in the etcd v2.1.x series of releases which uses fewer connections.
|
||||
|
||||
### I'm seeing a SSLv3 alert handshake failure when using SSL client authentication?
|
||||
|
||||
The `crypto/tls` package of `golang` checks the key usage of the certificate public key before using it.
|
||||
To use the certificate public key to do client auth, we need to add `clientAuth` to `Extended Key Usage` when creating the certificate public key.
|
||||
|
||||
Here is how to do it:
|
||||
|
||||
Add the following section to your openssl.cnf:
|
||||
|
||||
```
|
||||
[ ssl_client ]
|
||||
...
|
||||
extendedKeyUsage = clientAuth
|
||||
...
|
||||
```
|
||||
|
||||
When creating the cert be sure to reference it in the `-extensions` flag:
|
||||
|
||||
```
|
||||
$ openssl ca -config openssl.cnf -policy policy_anything -extensions ssl_client -out certs/machine.crt -infiles machine.csr
|
||||
```
|
||||
|
||||
### With peer certificate authentication I receive "certificate is valid for 127.0.0.1, not $MY_IP"
|
||||
Make sure that you sign your certificates with a Subject Name your member's public IP address. The `etcd-ca` tool for example provides an `--ip=` option for its `new-cert` command.
|
||||
|
||||
If you need your certificate to be signed for your member's FQDN in its Subject Name then you could use Subject Alternative Names (short IP SANs) to add your IP address. The `etcd-ca` tool provides `--domain=` option for its `new-cert` command, and openssl can make [it][alt-name] too.
|
||||
|
||||
[cfssl]: https://github.com/cloudflare/cfssl
|
||||
[tls-setup]: ../../hack/tls-setup
|
||||
[tls-guide]: https://github.com/coreos/docs/blob/master/os/generate-self-signed-certificates.md
|
||||
[alt-name]: http://wiki.cacert.org/FAQ/subjectAltName
|
||||
[auth]: authentication.md
|
||||
|
|
@ -1,81 +0,0 @@
|
|||
---
|
||||
title: Tuning
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
The default settings in etcd should work well for installations on a local network where the average network latency is low.
|
||||
However, when using etcd across multiple data centers or over networks with high latency you may need to tweak the heartbeat interval and election timeout settings.
|
||||
|
||||
The network isn't the only source of latency. Each request and response may be impacted by slow disks on both the leader and follower. Each of these timeouts represents the total time from request to successful response from the other machine.
|
||||
|
||||
## Time Parameters
|
||||
|
||||
The underlying distributed consensus protocol relies on two separate time parameters to ensure that nodes can handoff leadership if one stalls or goes offline.
|
||||
The first parameter is called the *Heartbeat Interval*.
|
||||
This is the frequency with which the leader will notify followers that it is still the leader.
|
||||
For best practices, the parameter should be set around round-trip time between members.
|
||||
By default, etcd uses a `100ms` heartbeat interval.
|
||||
|
||||
The second parameter is the *Election Timeout*.
|
||||
This timeout is how long a follower node will go without hearing a heartbeat before attempting to become leader itself.
|
||||
By default, etcd uses a `1000ms` election timeout.
|
||||
|
||||
Adjusting these values is a trade off.
|
||||
The value of heartbeat interval is recommended to be around the maximum of average round-trip time (RTT) between members, normally around 0.5-1.5x the round-trip time.
|
||||
If heartbeat interval is too low, etcd will send unnecessary messages that increase the usage of CPU and network resources.
|
||||
On the other side, a too high heartbeat interval leads to high election timeout. Higher election timeout takes longer time to detect a leader failure.
|
||||
The easiest way to measure round-trip time (RTT) is to use [PING utility][ping].
|
||||
|
||||
The election timeout should be set based on the heartbeat interval and average round-trip time between members.
|
||||
Election timeouts must be at least 10 times the round-trip time so it can account for variance in your network.
|
||||
For example, if the round-trip time between your members is 10ms then you should have at least a 100ms election timeout.
|
||||
|
||||
You should also set your election timeout to at least 5 to 10 times your heartbeat interval to account for variance in leader replication.
|
||||
For a heartbeat interval of 50ms you should set your election timeout to at least 250ms - 500ms.
|
||||
|
||||
The upper limit of election timeout is 50000ms (50s), which should only be used when deploying a globally-distributed etcd cluster.
|
||||
A reasonable round-trip time for the continental United States is 130ms, and the time between US and Japan is around 350-400ms.
|
||||
If your network has uneven performance or regular packet delays/loss then it is possible that a couple of retries may be necessary to successfully send a packet. So 5s is a safe upper limit of global round-trip time.
|
||||
As the election timeout should be an order of magnitude bigger than broadcast time, in the case of ~5s for a globally distributed cluster, then 50 seconds becomes a reasonable maximum.
|
||||
|
||||
The heartbeat interval and election timeout value should be the same for all members in one cluster. Setting different values for etcd members may disrupt cluster stability.
|
||||
|
||||
You can override the default values on the command line:
|
||||
|
||||
```sh
|
||||
# Command line arguments:
|
||||
$ etcd -heartbeat-interval=100 -election-timeout=500
|
||||
|
||||
# Environment variables:
|
||||
$ ETCD_HEARTBEAT_INTERVAL=100 ETCD_ELECTION_TIMEOUT=500 etcd
|
||||
```
|
||||
|
||||
The values are specified in milliseconds.
|
||||
|
||||
## Snapshots
|
||||
|
||||
etcd appends all key changes to a log file.
|
||||
This log grows forever and is a complete linear history of every change made to the keys.
|
||||
A complete history works well for lightly used clusters but clusters that are heavily used would carry around a large log.
|
||||
|
||||
To avoid having a huge log etcd makes periodic snapshots.
|
||||
These snapshots provide a way for etcd to compact the log by saving the current state of the system and removing old logs.
|
||||
|
||||
### Snapshot Tuning
|
||||
|
||||
Creating snapshots can be expensive so they're only created after a given number of changes to etcd.
|
||||
By default, snapshots will be made after every 10,000 changes.
|
||||
If etcd's memory usage and disk usage are too high, you can lower the snapshot threshold by setting the following on the command line:
|
||||
|
||||
```sh
|
||||
# Command line arguments:
|
||||
$ etcd -snapshot-count=5000
|
||||
|
||||
# Environment variables:
|
||||
$ ETCD_SNAPSHOT_COUNT=5000 etcd
|
||||
```
|
||||
|
||||
[ping]: https://en.wikipedia.org/wiki/Ping_(networking_utility)
|
||||
|
|
@ -1,122 +0,0 @@
|
|||
---
|
||||
title: Upgrade etcd from 2.1 to 2.2
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
In the general case, upgrading from etcd 2.0 to 2.1 can be a zero-downtime, rolling upgrade:
|
||||
- one by one, stop the etcd v2.0 processes and replace them with etcd v2.1 processes
|
||||
- after you are running all v2.1 processes, new features in v2.1 are available to the cluster
|
||||
|
||||
Before [starting an upgrade](#upgrade-procedure), read through the rest of this guide to prepare.
|
||||
|
||||
## Upgrade Checklists
|
||||
|
||||
### Upgrade Requirements
|
||||
|
||||
To upgrade an existing etcd deployment to 2.1, you must be running 2.0. If you’re running a version of etcd before 2.0, you must upgrade to [2.0][v2.0] before upgrading to 2.1.
|
||||
|
||||
Also, to ensure a smooth rolling upgrade, your running cluster must be healthy. You can check the health of the cluster by using `etcdctl cluster-health` command.
|
||||
|
||||
### Preparedness
|
||||
|
||||
Before upgrading etcd, always test the services relying on etcd in a staging environment before deploying the upgrade to the production environment.
|
||||
|
||||
You might also want to [backup your data directory][backup-datastore] for a potential [downgrade](#downgrade).
|
||||
|
||||
etcd 2.1 introduces a new [authentication][auth] feature, which is disabled by default. If your deployment depends on these, you may want to test the auth features before enabling them in production.
|
||||
|
||||
### Mixed Versions
|
||||
|
||||
While upgrading, an etcd cluster supports mixed versions of etcd members. The cluster is only considered upgraded once all its members are upgraded to 2.1.
|
||||
|
||||
Internally, etcd members negotiate with each other to determine the overall etcd cluster version, which controls the reported cluster version and the supported features. For example, if you are mid-upgrade, any 2.1 features (such as the the authentication feature mentioned above) won’t be available.
|
||||
|
||||
### Limitations
|
||||
|
||||
If you encounter any issues during the upgrade, you can attempt to restart the etcd process in trouble using a newer v2.1 binary to solve the problem. One known issue is that etcd v2.0.0 and v2.0.2 may panic during rolling upgrades due to an existing bug, which has been fixed since etcd v2.0.3.
|
||||
|
||||
It might take up to 2 minutes for the newly upgraded member to catch up with the existing cluster when the total data size is larger than 50MB (You can check the size of the existing snapshot to know about the rough data size). In other words, it is safest to wait for 2 minutes before upgrading the next member.
|
||||
|
||||
If you have even more data, this might take more time. If you have a data size larger than 100MB you should contact us before upgrading, so we can make sure the upgrades work smoothly.
|
||||
|
||||
### Downgrade
|
||||
|
||||
If all members have been upgraded to v2.1, the cluster will be upgraded to v2.1, and downgrade is **not possible**. If any member is still v2.0, the cluster will remain in v2.0, and you can go back to use v2.0 binary.
|
||||
|
||||
Please [backup your data directory][backup-datastore] of all etcd members if you want to downgrade the cluster, even if it is upgraded.
|
||||
|
||||
### Upgrade Procedure
|
||||
|
||||
#### 1. Check upgrade requirements.
|
||||
|
||||
```
|
||||
$ etcdctl cluster-health
|
||||
cluster is healthy
|
||||
member 6e3bd23ae5f1eae0 is healthy
|
||||
member 924e2e83e93f2560 is healthy
|
||||
member a8266ecf031671f3 is healthy
|
||||
|
||||
$ curl http://127.0.0.1:4001/version
|
||||
etcd 2.0.x
|
||||
```
|
||||
|
||||
#### 2. Stop the existing etcd process
|
||||
|
||||
You will see similar error logging from other etcd processes in your cluster. This is normal, since you just shut down a member.
|
||||
|
||||
```
|
||||
2015/06/23 15:45:09 sender: error posting to 6e3bd23ae5f1eae0: dial tcp 127.0.0.1:7002: connection refused
|
||||
2015/06/23 15:45:09 sender: the connection with 6e3bd23ae5f1eae0 became inactive
|
||||
2015/06/23 15:45:11 rafthttp: encountered error writing to server log stream: write tcp 127.0.0.1:53783: broken pipe
|
||||
2015/06/23 15:45:11 rafthttp: server streaming to 6e3bd23ae5f1eae0 at term 2 has been stopped
|
||||
2015/06/23 15:45:11 stream: error sending message: stopped
|
||||
2015/06/23 15:45:11 stream: stopping the stream server...
|
||||
```
|
||||
|
||||
You could [backup your data directory][backup-datastore] for data safety.
|
||||
|
||||
```
|
||||
$ etcdctl backup \
|
||||
--data-dir /var/lib/etcd \
|
||||
--backup-dir /tmp/etcd_backup
|
||||
```
|
||||
|
||||
#### 3. Drop-in etcd v2.1 binary and start the new etcd process
|
||||
|
||||
You will see the etcd publish its information to the cluster.
|
||||
|
||||
```
|
||||
2015/06/23 15:45:39 etcdserver: published {Name:infra2 ClientURLs:[http://localhost:4002]} to cluster e9c7614f68f35fb2
|
||||
```
|
||||
|
||||
You could verify the cluster becomes healthy.
|
||||
|
||||
```
|
||||
$ etcdctl cluster-health
|
||||
cluster is healthy
|
||||
member 6e3bd23ae5f1eae0 is healthy
|
||||
member 924e2e83e93f2560 is healthy
|
||||
member a8266ecf031671f3 is healthy
|
||||
```
|
||||
|
||||
#### 4. Repeat step 2 to step 3 for all other members
|
||||
|
||||
#### 5. Finish
|
||||
|
||||
When all members are upgraded, you will see the cluster is upgraded to 2.1 successfully:
|
||||
|
||||
```
|
||||
2015/06/23 15:46:35 etcdserver: updated the cluster version from 2.0.0 to 2.1.0
|
||||
```
|
||||
|
||||
```
|
||||
$ curl http://127.0.0.1:4001/version
|
||||
{"etcdserver":"2.1.x","etcdcluster":"2.1.0"}
|
||||
```
|
||||
|
||||
[auth]: auth_api.md
|
||||
[backup-datastore]: admin_guide.md#backing-up-the-datastore
|
||||
[v2.0]: https://github.com/coreos/etcd/releases/tag/v2.0.13
|
||||
|
|
@ -1,138 +0,0 @@
|
|||
---
|
||||
title: Upgrade etcd from 2.1 to 2.2
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
In the general case, upgrading from etcd 2.1 to 2.2 can be a zero-downtime, rolling upgrade:
|
||||
|
||||
- one by one, stop the etcd v2.1 processes and replace them with etcd v2.2 processes
|
||||
- after you are running all v2.2 processes, new features in v2.2 are available to the cluster
|
||||
|
||||
Before [starting an upgrade](#upgrade-procedure), read through the rest of this guide to prepare.
|
||||
|
||||
## Upgrade Checklists
|
||||
|
||||
### Upgrade Requirement
|
||||
|
||||
To upgrade an existing etcd deployment to 2.2, you must be running 2.1. If you’re running a version of etcd before 2.1, you must upgrade to [2.1][v2.1] before upgrading to 2.2.
|
||||
|
||||
Also, to ensure a smooth rolling upgrade, your running cluster must be healthy. You can check the health of the cluster by using `etcdctl cluster-health` command.
|
||||
|
||||
### Preparedness
|
||||
|
||||
Before upgrading etcd, always test the services relying on etcd in a staging environment before deploying the upgrade to the production environment.
|
||||
|
||||
You might also want to [backup the data directory][backup-datastore] for a potential [downgrade].
|
||||
|
||||
### Mixed Versions
|
||||
|
||||
While upgrading, an etcd cluster supports mixed versions of etcd members. The cluster is only considered upgraded once all its members are upgraded to 2.2.
|
||||
|
||||
Internally, etcd members negotiate with each other to determine the overall etcd cluster version, which controls the reported cluster version and the supported features.
|
||||
|
||||
### Limitations
|
||||
|
||||
If you have a data size larger than 100MB you should contact us before upgrading, so we can make sure the upgrades work smoothly.
|
||||
|
||||
Every etcd 2.2 member will do health checking across the cluster periodically. etcd 2.1 member does not support health checking. During the upgrade, etcd 2.2 member will log warning about the unhealthy state of etcd 2.1 member. You can ignore the warning.
|
||||
|
||||
### Downgrade
|
||||
|
||||
If all members have been upgraded to v2.2, the cluster will be upgraded to v2.2, and downgrade is **not possible**. If any member is still v2.1, the cluster will remain in v2.1, and you can go back to use v2.1 binary.
|
||||
|
||||
Please [backup the data directory][backup-datastore] of all etcd members if you want to downgrade the cluster, even if it is upgraded.
|
||||
|
||||
### Upgrade Procedure
|
||||
|
||||
In the example, we upgrade a three member v2.1 cluster running on local machine.
|
||||
|
||||
#### 1. Check upgrade requirements.
|
||||
|
||||
```
|
||||
$ etcdctl cluster-health
|
||||
member 6e3bd23ae5f1eae0 is healthy: got healthy result from http://localhost:22379
|
||||
member 924e2e83e93f2560 is healthy: got healthy result from http://localhost:32379
|
||||
member a8266ecf031671f3 is healthy: got healthy result from http://localhost:12379
|
||||
cluster is healthy
|
||||
|
||||
$ curl http://localhost:4001/version
|
||||
{"etcdserver":"2.1.x","etcdcluster":"2.1.0"}
|
||||
```
|
||||
|
||||
#### 2. Stop the existing etcd process
|
||||
|
||||
You will see similar error logging from other etcd processes in your cluster. This is normal, since you just shut down a member and the connection is broken.
|
||||
|
||||
```
|
||||
2015/09/2 09:48:35 etcdserver: failed to reach the peerURL(http://localhost:12380) of member a8266ecf031671f3 (Get http://localhost:12380/version: dial tcp [::1]:12380: getsockopt: connection refused)
|
||||
2015/09/2 09:48:35 etcdserver: cannot get the version of member a8266ecf031671f3 (Get http://localhost:12380/version: dial tcp [::1]:12380: getsockopt: connection refused)
|
||||
2015/09/2 09:48:35 rafthttp: failed to write a8266ecf031671f3 on stream Message (write tcp 127.0.0.1:32380->127.0.0.1:64394: write: broken pipe)
|
||||
2015/09/2 09:48:35 rafthttp: failed to write a8266ecf031671f3 on pipeline (dial tcp [::1]:12380: getsockopt: connection refused)
|
||||
2015/09/2 09:48:40 etcdserver: failed to reach the peerURL(http://localhost:7001) of member a8266ecf031671f3 (Get http://localhost:7001/version: dial tcp [::1]:12380: getsockopt: connection refused)
|
||||
2015/09/2 09:48:40 etcdserver: cannot get the version of member a8266ecf031671f3 (Get http://localhost:12380/version: dial tcp [::1]:12380: getsockopt: connection refused)
|
||||
2015/09/2 09:48:40 rafthttp: failed to heartbeat a8266ecf031671f3 on stream MsgApp v2 (write tcp 127.0.0.1:32380->127.0.0.1:64393: write: broken pipe)
|
||||
```
|
||||
|
||||
You will see logging output like this from ungraded member due to a mixed version cluster. You can ignore this while upgrading.
|
||||
|
||||
```
|
||||
2015/09/2 09:48:45 etcdserver: the etcd version 2.1.2+git is not up-to-date
|
||||
2015/09/2 09:48:45 etcdserver: member a8266ecf031671f3 has a higher version &{2.2.0-rc.0+git 2.1.0}
|
||||
```
|
||||
|
||||
You will also see logging output like this from the newly upgraded member, since etcd 2.1 member does not support health checking. You can ignore this while upgrading.
|
||||
|
||||
```
|
||||
2015-09-02 09:55:42.691384 W | rafthttp: the connection to peer 6e3bd23ae5f1eae0 is unhealthy
|
||||
2015-09-02 09:55:42.705626 W | rafthttp: the connection to peer 924e2e83e93f2560 is unhealthy
|
||||
|
||||
```
|
||||
|
||||
[Backup your data directory][backup-datastore] for data safety.
|
||||
|
||||
```
|
||||
$ etcdctl backup \
|
||||
--data-dir /var/lib/etcd \
|
||||
--backup-dir /tmp/etcd_backup
|
||||
```
|
||||
|
||||
#### 3. Drop-in etcd v2.2 binary and start the new etcd process
|
||||
|
||||
Now, you can start the etcd v2.2 binary with the previous configuration.
|
||||
You will see the etcd start and publish its information to the cluster.
|
||||
|
||||
```
|
||||
2015-09-02 09:56:46.117609 I | etcdserver: published {Name:infra2 ClientURLs:[http://localhost:22380]} to cluster e9c7614f68f35fb2
|
||||
```
|
||||
|
||||
You could verify the cluster becomes healthy.
|
||||
|
||||
```
|
||||
$ etcdctl cluster-health
|
||||
member 6e3bd23ae5f1eae0 is healthy: got healthy result from http://localhost:22379
|
||||
member 924e2e83e93f2560 is healthy: got healthy result from http://localhost:32379
|
||||
member a8266ecf031671f3 is healthy: got healthy result from http://localhost:12379
|
||||
cluster is healthy
|
||||
```
|
||||
|
||||
#### 4. Repeat step 2 to step 3 for all other members
|
||||
|
||||
#### 5. Finish
|
||||
|
||||
When all members are upgraded, you will see the cluster is upgraded to 2.2 successfully:
|
||||
|
||||
```
|
||||
2015-09-02 09:56:54.896848 N | etcdserver: updated the cluster version from 2.1 to 2.2
|
||||
```
|
||||
|
||||
```
|
||||
$ curl http://127.0.0.1:4001/version
|
||||
{"etcdserver":"2.2.x","etcdcluster":"2.2.0"}
|
||||
```
|
||||
|
||||
[backup-datastore]: admin_guide.md#backing-up-the-datastore
|
||||
[downgrade]: #downgrade
|
||||
[v2.1]: https://github.com/coreos/etcd/releases/tag/v2.1.2
|
||||
|
|
@ -1,127 +0,0 @@
|
|||
---
|
||||
title: Upgrade etcd from 2.2 to 2.3
|
||||
---
|
||||
|
||||
**This is the documentation for etcd2 releases. Read [etcd3 doc][v3-docs] for etcd3 releases.**
|
||||
|
||||
[v3-docs]: ../docs.md#documentation
|
||||
|
||||
In the general case, upgrading from etcd 2.2 to 2.3 can be a zero-downtime, rolling upgrade:
|
||||
- one by one, stop the etcd v2.2 processes and replace them with etcd v2.3 processes
|
||||
- after running all v2.3 processes, new features in v2.3 are available to the cluster
|
||||
|
||||
Before [starting an upgrade](#upgrade-procedure), read through the rest of this guide to prepare.
|
||||
|
||||
### Upgrade Checklists
|
||||
|
||||
#### Upgrade Requirements
|
||||
|
||||
To upgrade an existing etcd deployment to 2.3, the running cluster must be 2.2 or greater. If it's before 2.2, please upgrade to [2.2](https://github.com/coreos/etcd/releases/tag/v2.2.0) before upgrading to 2.3.
|
||||
|
||||
Also, to ensure a smooth rolling upgrade, the running cluster must be healthy. You can check the health of the cluster by using the `etcdctl cluster-health` command.
|
||||
|
||||
#### Preparation
|
||||
|
||||
Before upgrading etcd, always test the services relying on etcd in a staging environment before deploying the upgrade to the production environment.
|
||||
|
||||
Before beginning, [backup the etcd data directory](admin_guide.md#backing-up-the-datastore). Should something go wrong with the upgrade, it is possible to use this backup to[downgrade](#downgrade) back to existing etcd version.
|
||||
|
||||
#### Mixed Versions
|
||||
|
||||
While upgrading, an etcd cluster supports mixed versions of etcd members, and operates with the protocol of the lowest common version. The cluster is only considered upgraded once all of its members are upgraded to version 2.3. Internally, etcd members negotiate with each other to determine the overall cluster version, which controls the reported version and the supported features.
|
||||
|
||||
#### Limitations
|
||||
|
||||
It might take up to 2 minutes for the newly upgraded member to catch up with the existing cluster when the total data size is larger than 50MB. Check the size of a recent snapshot to estimate the total data size. In other words, it is safest to wait for 2 minutes between upgrading each member.
|
||||
|
||||
For a much larger total data size, 100MB or more , this one-time process might take even more time. Administrators of very large etcd clusters of this magnitude can feel free to contact the [etcd team][etcd-contact] before upgrading, and we’ll be happy to provide advice on the procedure.
|
||||
|
||||
#### Downgrade
|
||||
|
||||
If all members have been upgraded to v2.3, the cluster will be upgraded to v2.3, and downgrade from this completed state is **not possible**. If any single member is still v2.2, however, the cluster and its operations remains “v2.2”, and it is possible from this mixed cluster state to return to using a v2.2 etcd binary on all members.
|
||||
|
||||
Please [backup the data directory](admin_guide.md#backing-up-the-datastore) of all etcd members to make downgrading the cluster possible even after it has been completely upgraded.
|
||||
|
||||
### Upgrade Procedure
|
||||
|
||||
|
||||
This example details the upgrade of a three-member v2.2 ectd cluster running on a local machine.
|
||||
|
||||
#### 1. Check upgrade requirements.
|
||||
|
||||
Is the the cluster healthy and running v.2.2.x?
|
||||
|
||||
```
|
||||
$ etcdctl cluster-health
|
||||
member 6e3bd23ae5f1eae0 is healthy: got healthy result from http://localhost:22379
|
||||
member 924e2e83e93f2560 is healthy: got healthy result from http://localhost:32379
|
||||
member a8266ecf031671f3 is healthy: got healthy result from http://localhost:12379
|
||||
cluster is healthy
|
||||
|
||||
$ curl http://localhost:4001/version
|
||||
{"etcdserver":"2.2.x","etcdcluster":"2.2.0"}
|
||||
```
|
||||
|
||||
#### 2. Stop the existing etcd process
|
||||
|
||||
When each etcd process is stopped, expected errors will be logged by other cluster members. This is normal since a cluster member connection has been (temporarily) broken:
|
||||
|
||||
```
|
||||
2016-03-11 09:50:49.860319 E | rafthttp: failed to read 8211f1d0f64f3269 on stream Message (unexpected EOF)
|
||||
2016-03-11 09:50:49.860335 I | rafthttp: the connection with 8211f1d0f64f3269 became inactive
|
||||
2016-03-11 09:50:51.023804 W | etcdserver: failed to reach the peerURL(http://127.0.0.1:12380) of member 8211f1d0f64f3269 (Get http://127.0.0.1:12380/version: dial tcp 127.0.0.1:12380: getsockopt: connection refused)
|
||||
2016-03-11 09:50:51.023821 W | etcdserver: cannot get the version of member 8211f1d0f64f3269 (Get http://127.0.0.1:12380/version: dial tcp 127.0.0.1:12380: getsockopt: connection refused)
|
||||
```
|
||||
|
||||
It’s a good idea at this point to [backup the etcd data directory](https://github.com/coreos/etcd/blob/7f7e2cc79d9c5c342a6eb1e48c386b0223cf934e/Documentation/admin_guide.md#backing-up-the-datastore) to provide a downgrade path should any problems occur:
|
||||
|
||||
```
|
||||
$ etcdctl backup \
|
||||
--data-dir /var/lib/etcd \
|
||||
--backup-dir /tmp/etcd_backup
|
||||
```
|
||||
|
||||
#### 3. Drop-in etcd v2.3 binary and start the new etcd process
|
||||
|
||||
The new v2.3 etcd will publish its information to the cluster:
|
||||
|
||||
```
|
||||
09:58:25.938673 I | etcdserver: published {Name:infra1 ClientURLs:[http://localhost:12379]} to cluster 524400597fb1d5f6
|
||||
```
|
||||
|
||||
Verify that each member, and then the entire cluster, becomes healthy with the new v2.3 etcd binary:
|
||||
|
||||
```
|
||||
$ etcdctl cluster-health
|
||||
member 6e3bd23ae5f1eae0 is healthy: got healthy result from http://localhost:22379
|
||||
member 924e2e83e93f2560 is healthy: got healthy result from http://localhost:32379
|
||||
member a8266ecf031671f3 is healthy: got healthy result from http://localhost:12379
|
||||
cluster is healthy
|
||||
```
|
||||
|
||||
|
||||
Upgraded members will log warnings like the following until the entire cluster is upgraded. This is expected and will cease after all etcd cluster members are upgraded to v2.3:
|
||||
|
||||
```
|
||||
2016-03-11 09:58:26.851837 W | etcdserver: the local etcd version 2.2.0 is not up-to-date
|
||||
2016-03-11 09:58:26.851854 W | etcdserver: member c02c70ede158499f has a higher version 2.3.0
|
||||
```
|
||||
|
||||
#### 4. Repeat step 2 to step 3 for all other members
|
||||
|
||||
#### 5. Finish
|
||||
|
||||
When all members are upgraded, the cluster will report upgrading to 2.3 successfully:
|
||||
|
||||
```
|
||||
2016-03-11 10:03:01.583392 N | etcdserver: updated the cluster version from 2.2 to 2.3
|
||||
```
|
||||
|
||||
```
|
||||
$ curl http://127.0.0.1:4001/version
|
||||
{"etcdserver":"2.3.x","etcdcluster":"2.3.0"}
|
||||
```
|
||||
|
||||
|
||||
[etcd-contact]: https://coreos.com/etcd/?
|
||||
|
||||
24
README.md
24
README.md
|
|
@ -80,13 +80,13 @@ Join by phone: +1 405-792-0633 PIN: 299 906#
|
|||
|
||||
The easiest way to get etcd is to use one of the pre-built release binaries which are available for OSX, Linux, Windows, and Docker on the [release page][github-release].
|
||||
|
||||
For more installation guides, please check out [play.etcd.io](http://play.etcd.io) and [operating etcd](https://github.com/etcd-io/etcd/tree/master/Documentation#operating-etcd-clusters).
|
||||
For more installation guides, please check out [play.etcd.io](http://play.etcd.io) and [operating etcd](https://etcd.io/docs/latest/op-guide).
|
||||
|
||||
For those wanting to try the very latest version, [build the latest version of etcd][dl-build] from the `master` branch. This first needs [*Go*](https://golang.org/) installed (version 1.13+ is required). All development occurs on `master`, including new features and bug fixes. Bug fixes are first targeted at `master` and subsequently ported to release branches, as described in the [branch management][branch-management] guide.
|
||||
|
||||
[github-release]: https://github.com/etcd-io/etcd/releases
|
||||
[branch-management]: ./Documentation/branch_management.md
|
||||
[dl-build]: ./Documentation/dl_build.md#build-the-latest-version
|
||||
[branch-management]: https://etcd.io/docs/latest/branch-management
|
||||
[dl-build]: https://etcd.io/docs/latest/dl-build#build-the-latest-version
|
||||
|
||||
### Running etcd
|
||||
|
||||
|
|
@ -123,7 +123,7 @@ etcdctl get mykey
|
|||
etcd is now running and serving client requests. For more, please check out:
|
||||
|
||||
- [Interactive etcd playground](http://play.etcd.io)
|
||||
- [Animated quick demo](./Documentation/demo.md)
|
||||
- [Animated quick demo](https://etcd.io/docs/latest/demo)
|
||||
|
||||
### etcd TCP ports
|
||||
|
||||
|
|
@ -163,13 +163,13 @@ Now it's time to dig into the full etcd API and other guides.
|
|||
- Use TLS to [secure an etcd cluster][security].
|
||||
- [Tune etcd][tuning].
|
||||
|
||||
[fulldoc]: ./Documentation/docs.md
|
||||
[api]: ./Documentation/dev-guide/api_reference_v3.md
|
||||
[clustering]: ./Documentation/op-guide/clustering.md
|
||||
[configuration]: ./Documentation/op-guide/configuration.md
|
||||
[integrations]: ./Documentation/integrations.md
|
||||
[security]: ./Documentation/op-guide/security.md
|
||||
[tuning]: ./Documentation/tuning.md
|
||||
[fulldoc]: https://etcd.io/docs/latest
|
||||
[api]: https://etcd.io/docs/latest/learning/api
|
||||
[clustering]: https://etcd.io/docs/latest/op-guide/clustering
|
||||
[configuration]: https://etcd.io/docs/latest/op-guide/configuration
|
||||
[integrations]: https://etcd.io/docs/latest/integrations
|
||||
[security]: https://etcd.io/docs/latest/op-guide/security
|
||||
[tuning]: https://etcd.io/docs/latest/tuning
|
||||
|
||||
## Contact
|
||||
|
||||
|
|
@ -184,7 +184,7 @@ See [CONTRIBUTING](CONTRIBUTING.md) for details on submitting patches and the co
|
|||
|
||||
## Reporting bugs
|
||||
|
||||
See [reporting bugs](Documentation/reporting_bugs.md) for details about reporting any issues.
|
||||
See [reporting bugs](https://etcd.io/docs/latest/reporting-bugs) for details about reporting any issues.
|
||||
|
||||
## Reporting a security vulnerability
|
||||
|
||||
|
|
|
|||
3
test
3
test
|
|
@ -391,7 +391,7 @@ function shellcheck_pass {
|
|||
|
||||
function markdown_you_pass {
|
||||
# eschew you
|
||||
yous=$(find . -name \*.md ! -path './vendor/*' ! -path './Documentation/v2/*' ! -path './gopath.proto/*' -exec grep -E --color "[Yy]ou[r]?[ '.,;]" {} + || true)
|
||||
yous=$(find . -name \*.md ! -path './vendor/*' ! -path './Documentation/*' ! -path './gopath.proto/*' -exec grep -E --color "[Yy]ou[r]?[ '.,;]" {} + || true)
|
||||
if [ -n "$yous" ]; then
|
||||
echo -e "found 'you' in documentation:\\n${yous}"
|
||||
exit 255
|
||||
|
|
@ -613,7 +613,6 @@ function fmt_pass {
|
|||
# TODO: add "unparam"
|
||||
for p in shellcheck \
|
||||
markdown_you \
|
||||
markdown_marker \
|
||||
goword \
|
||||
gofmt \
|
||||
govet \
|
||||
|
|
|
|||
Loading…
Reference in New Issue